Choose timezone
Your profile timezone:
The Linux Plumbers Conference is the premier event for developers working at all levels of the plumbing layer and beyond.
Maintaining A Stable Real-time Kernel Patchset
josephtsalisbury@gmail.com
jsalisbury@kernel.org
Abstract:
The Real Time Linux collaborative project coordinates the maintenance and hosts the repositories for the PREEMPT_RT patchset[0]. This patchset provides the logic for changing a generic vanilla kernel into a real-time operating system.
The real-time patchset is developed in parallel with the mainline kernel. Once mainline is released, the patchset follows it into the next major version. However, for long-term stable kernels (LTS), a stable version of the patchset is continually maintained until the end-of-life (EOL) of the LTS kernel.
Joseph has recently become the maintainer of the 5.15 stable release of the real time kernel. He will use his experiences of coming up to speed on this work to present what it takes to be a kernel maintainer. This will be helpful for those that want to learn the workflow of maintaining an upstream project and learn about commonly used upstream tools. It will also be helpful to those that want to better understand the stable maintenance process in general. Some topics covered will be:
A large component of this talk will be the SRT tool[1], which was created by Daniel Wagner. This tool provides a scripted mechanism to maintain stable real-time trees. SRT is installed via pip in Python 3 [2] with the src available in github [3]. It is possible to use SRT for other projects hosted on kernel.org. SRT provides a way to rebase and merge kernel stable updates and commit / tag in a consistent / repeatable way. SRT uses the kernel uploaded (KUP)[4], which provides a way to upload a project's source to kernel.org.
[0] https://wiki.linuxfoundation.org/realtime/start
[1] https://stable-rt-tools.readthedocs.io/en/latest/index.html
[2] https://pypi.org/project/stable-rt-tools/
[3] https://github.com/igaw/stable-rt-tools
[4] https://git.kernel.org/pub/scm/utils/kup/kup.git
Program verification, ie, producing a proof that code matches its specification, can be seen as the ultimate form of bug finding. Nevertheless, program verification is widely considered to be difficult and time consuming. Furthermore, in the case of the Linux kernel, any verification effort is likely quickly out of date, given the rate of change in the code base. Still, it is not necessarily the case that a change in the source code will have an impact on the specifications or their proof. In this talk, we present our experiments on applying verification to the Linux kernel scheduler, studying the resistance to change of the verification effort and the bugs and missed optimization opportunities found.
Calling sleeping locks in a non-preemptible context is not allowed because it causes a "BUG: scheduling while atomic" error. This problem is particularly relevant for PREEMPT_RT kernels, which convert all spin locks into sleeping locks. As a result, unexpected scheduling can occur in non-preemptible contexts. One way to detect this issue is by annotating such sleeping functions with might_resched(), which triggers a warning on PREEMPT_RT systems.
Although PREEMPT_RT has been around for a while, new bugs of this type continue to emerge from various subsystems. Given the straightforward nature of this bug, I developed a prototype static tool based on graph search called rtlockscope. This tool aims to scan the entire kernel source code for such issues. Rtlockscope is similar to Gary Guo's klint, which detects this problem in Rust code. However, unlike klint, rtlockscope cannot rely heavily on scheduling/preemption annotations because the Linux kernel code lacks them. Therefore, the autodetection must be more sophisticated, which is the primary challenge.
The current (unfinished) state of rtlockscope will be presented, along with some ideas for improving it.
Data Placement has been one of major the sources of innovation in storage. Specifically in NAND Memory, technologies such as Open-Channel SSDs, Key-Value SSDs, Multi Stream, Zoned Namespaces (ZNS), and lately Flexible Data Placement (FDP) have attempted at covering different use-cases. While there is overlap among several of these technologies, they exhibit significant differences when it comes to they way they can be adopted a the system level.
In this talk, we will talk about the evolution of these data placement technologies with a focus on the Linux ecosystem support, and the big impact that vertical system integration is having in the adoption of these technologies in enterprise and hyper-scale environments. Specifically, we will cover: (i) read/write model, where we will detail the changes needed in the I/O path for each technology and the effects this has in the OS; (ii) guarantees to reduce Write Amplification (WAF), where we will cover how each technology is able to reduce end-to-end WAF in different File-System and Application setups; and (iii) ecosystem complexity, where we will comment on the Kernel, library, and application modifications that each technology imposes. Here, we will focus on the the ongoing work to make Linux ready for FDP NVMe SSDs. In the process, we will provide our vision on where each technology fits in the NVMe landscape when it comes to enable different types of memory.
Applications with large in-memory caches like databases or storage nodes suffer
heavily from downtime when upgrading the kernel. They need to go out of
commission not only for the reboot time, but also for the time it takes to warm
up the caches again. This talk proposes a mechanism that allows handing over
userspace memory to the next kernel after a kexec. This allows such applications
to persist their caches to achieve fast kernel upgrades with minimal downtime.
It can also be used with CRIU to avoid the need for modifying the applications
to use this mechanism. Other use cases include doing a "live update" for
container hosts, allowing kernel upgrades with low downtime for the container
workloads.
It is critical to boot the kexec kernel fast in the system live-update scenarios. As one challenge in this case, a kexec procedure today always initializes ACPI in the same way as a cold reboot, which can take more than 100ms on latest x86 servers. Most of the time is spent on table loading, interpreting and finding idle states, which practically won't have changing side effects across a kexec reboot, as in the case of system software live-update. In order to reduce kexec downtime, an optimization is to preserve (or cache) the ACPI kernel state in memory, eliminating expensive IO and DSDT data structure parsing if the result is guaranteed to be the same.
This requires 1) a mechanism to preserve data between the running kernel and kexec target kernel, (forming an ABI that needs to be carefully defined for compatibility), 2) a new ACPI mode (e.g. a new "acpi=restore" cmdline parameter) that instructs the new kernel to recreate necessary states from memory.
With these extensions, we are looking to further reducing kexec time by 100-300 ms (on top of previous features such as HVO, parallel SMP boot and whitelist based PCI device probing).
This presentation will give an overview of the current state in our ACPI driver, explain the proposed approach at hand including its motivations and contraints, explore and relates to others' work, then discuss possible solutions and look at the next steps.
The email workflow brought the kernel to life, saw it through immense growth, and into widespread popularity. However, it seems to be reaching its limits, prompting Linus to say we need to "find ways to get away from the email patch model" to make maintainer life easier.
Kernel workflow evolution (1991 - start, 2002 - BitKeeper, 2005 - Git, 2008 - Patchwork) seems to have stopped fifteen years ago. Another change might be due. We don't know what it will be, and a single solution is unlikely, but we know one of them works: GitLab.
We'll explore how it helps some maintainers and developers in the kernel and adjacent projects: from tracking issues, running CI, to the actual MR workflow, and demonstrate how to try all of that easily.
Gitlab is a mature integrated development platform with an MIT-licensed Open Core built by a company with open source values. Apart from the canonical instance on gitlab.com (with paid features financing development), multiple open-source communities, some companies working in open source, and many technical universities manage their own instances.
Reference counting in Linux kernel is often implemented using
conditional atomic increment/decrement operations on a counter. These
atomic operations can become a scalability bottleneck with increasing
numbers of CPUs. The RCURef patch series 1 and Nginx refcount
scalability issues 2 are recent examples where the refcount bottleneck
significantly degraded application throughput.
Per-CPU refcounting 2 avoids memory contention by distributing
refcount operations across CPUs. However, this is not free:
on a 64-bit system, the per-object space overhead for per-CPU
refcounting is 72 bytes plus eight additional bytes per CPU.
The hazard-pointers technique 3 dynamically distributes refcounting,
and is especially useful in cases where reference counters are
acquired conditionally, for example, via using kref_get_unless_zero().
It can greatly improve scalability, resulting in userspace use [4,5]
and also inclusion into the C++26 standard 6.
Moreover, hazard pointers can be significantly more space-efficient than
per-CPU refcounting. For large numbers of objects on a 64-bit system,
only 16 bytes is required per object, which is a great savings compared
to 72 bytes plus eight more bytes per CPU for per-CPU refcounting.
Of course, there are advantages to per-CPU refcounting, for example,
given large numbers of tasks, each having a long-lived reference to
one of a small number of objects. On a 64-bit system, the current
hazard-pointers prototype incurs a per-task space overhead of 128 bytes. In
contrast, per-CPU refcounting incurs no per-task space overhead
whatsoever.
Thus, hazard pointers is most likely to be the right tool for the job in
cases of high contention on reference counters protecting large numbers
of objects.
In this talk, we will present the design 7 and implementation of
hazard pointers, including Linux-kernel-specific challenges. We will
also present examples of hazard-pointers usage, performance results and
comparison to other techniques, including RCU and Sleepable-RCU.
LPC Networking track is an in-person (and virtual) manifestation of the netdev mailing list, bringing together developers, users and vendors to discuss topics related to Linux networking. Relevant topics span from proposals for kernel changes, through user space tooling, to presenting interesting use cases, new protocols or new, interesting problems waiting for a solution.
Energy Efficient Ethernet (EEE) promises a greener future for networking, but its implementation within the Linux kernel has been a bit of a wild west. Inconsistent interpretations of the IEEE 802.3 standard have led to a patchwork of EEE implementations, often riddled with errors or simply blacklisted due to complexity.
This presentation takes you on a journey through the EEE landscape, shedding light on the common pitfalls and misconceptions that have plagued its adoption. The speaker, a seasoned wrangler of network drivers, will unveil the recently enhanced PHY framework, a powerful tool designed to tame the EEE wilderness and bring order to the chaos.
Discover how this framework streamlines EEE initialization, minimizes errors, and paves the way for a more energy-efficient future. Learn from the mistakes of others as the speaker highlights common implementation blunders and provides expert guidance on how to avoid them. Whether you're a seasoned kernel hacker or a curious network enthusiast, this presentation promises to equip you with the knowledge and tools needed to conquer the EEE frontier and build a more sustainable network ecosystem.
There are devices out-there that have several front-facing ports that
are connected to the same interface, through different physical
configurations.
Support for having multiple PHYs, each driving one port, is ongoing and
was presented at netdevconf 0x17.
However, support for having several ports (or connectors) connected to
the same MAC isn't there yet, this talk aims at presenting the plans for
that and discuss the challenges encountered.
Having a proper port representation would allow end-users to enumerate,
and manually control each individual port to select/unselect it,
get its technology such as Fiber/Copper.
It will also help us developers get some clean and precise info on the
port, to know for example if this is a 2 lanes or 4 lanes BaseT port, if
it's a Fiber port without SFP, and cleanly deal with newly supported
features such as PoE, which is really specific to a Port and not a PHY
device as it's represented today.
This is especially relevant for embedded use-cases, where most of the
time all these information are exposed through device-tree.
This work will also be used as the main interface to control the
to-be-introduced multiplexers, allowing to have several front-facing ports
controlled by either the same PHY, or different PHYS, themselved multiplexed.
This talk will therefore sum-up the use-cases, current state of the
aforementioned work, and lead to discussions on the various challenges
on which the inputs from the Net community could help greatly.
The High-availability Seamless Redundancy (HSR) is the protocol, which is supposed to increase the reliability
of network with no decrease of its availability. Required changes to HW setup - compared to e.g. RSTP -
are minimal. Moreover, some switch ICs provide possibility to offload HSR specific operations.
With contemporary Linux kernel the HSR is supported in DANH and RedBOX modes with only software mode as well as
in-HW offloading for selected switch ICs.
During the network's track session a very short explanation of HSR's idea of operation would be presented. Afterwards,
status of contemporary Linux HSR driver would be examined - with emphasis on currently supported features and QEMU based testing.
The presentation would be concluded with discussion about possible improvements.
rtnl_lock() is the "Big Kernel Lock" used all over the networking subsystem.
It serialises various rtnetlink requests, including adding/removing/dumping networking devices, IPv4 and IPv6 addresses, routes, etc.
Since 4.14, there has been an infrastructure not to hold rtnl_lock() for some types of requests, and a lot of work has been done to convert request handlers to RTNL-free. For example, since 6.9, IPv6 addresses and IPv4 routes can be dumped under RCU instead of rtnl_lock().
While significant improvements have been made on the reader side, rtnl_lock() is still a huge pain on the writer side.
One of our services creates thousands of network namespaces and a small number of devices in each netns. Even though the rtnetlink requests are issued per netns concurrently in userspace, they are serialised in the kernel, so setting up a single host takes 10+ minutes.
This talk gives a short refresher of rtnl_lock(), introduces recent updates to lower RTNL pressure, and suggests changes, per-netns RTNL, focusing on gaining more concurrency for many netns workloads.
Three years ago, we had the pleasure of giving a talk at Linux Plumbers about rough edges in BPF user experience. Attendees might recall that we found quite a few reasons for the panda to be sad about BPF UX back then.
This time, we would like to come back and present an assortment of snags we have encountered in the Linux network stack itself:
127/8 for IPv6?TS.Recent TCP timestamp resolution can lead to port exhaustion?IP_BIND_ADDRESS_NO_PORT does not work the way you think for UDP?listen() semantics for UDP make sense when we consider QUIC?Some of these problems we have worked on and managed to solve in collaboration with the Linux upstream community. Some we have only discussed publicly but intend to propose and contribute a solution for, while others we just acknowledge and present a workaround recipe, if one exists.
We hope to engage the audience to learn who else has run into any of the presented obstacles, are there any alternative approaches that we have not considered, and to collect input on how to best solve them.
The kernel networking stack provides a mechanism for enabling non-temporal (NT) writes at the NIC level (via ethtool). This setting is useful, but it is device wide and there may be other places in the kernel where NT writes might be desirable by userland.
This talk will discuss how the existing mechanism works and describe a case for why more fine grained control of NT writes by userland might be desirable. Application architectures where this might apply and performance numbers from a microbenchmark as described in an RFC sent to the mailing list will be discussed and examined.
Virtualization comes with overhead, and networking is no exception. In a typical virtualized scenario, the traffic traverses the network stacks of both the guest and the host. This presentation will introduce software and hardware solutions to minimize this overhead.
One of the challenges a virtualized network stack will face is the consistency of policy to assign received packets to queues. The use of multiqueues is essential for scalability, but inconsistent packet assignment policies of the guest and the host result in unnecessary synchronization among processors, hurting scalability. The current virtio specification allows negotiating the use of a packet assignment policy called RSS. We will present an RSS implementation utilizing eBPF in QEMU. We will also propose to add a new feature to the tuntap device to pass hash values calculated for RSS to the guest via vhost-net so that the guest can reuse them to assign packets to internal queues, reducing the duplication of work further. These kernel mechanisms are potentially useful to implement other packet assignment policies the virtio spec may gain in the future.
While software optimizations are important for general setups, dedicated network virtualization hardware is the best choice for optimized virtualization environments. Some NICs support virtualization based on the PCI Express SR-IOV specification. We have implemented an emulation of Intel's NIC that supports SR-IOV in QEMU to ease testing SR-IOV. In addition, we are also proposing to add SR-IOV support to QEMU's virtio implementation as a preparation for applying it to vDPA.
Shared Memory Communication (SMC) is a high-performance, socket-based stack that operates within kernel space. By leveraging shared memory technology, SMC enhances communication speeds while preserving the TCP socket API for userspace. Consequently, most TCP applications can seamlessly transition from TCP to SMC to achieve better performance without requiring any code modifications.
Recent AI training demands increasingly higher bandwidth, making userspace RDMA widely adopted in AI applications. TCP device memory aims to eliminate memory copying between main memory and GPU memory, and has made considerable progress. However, while SMC-R natively supports RDMA, enabling zero-copy functionality is straightforward for SMC-R, it remains nearly impossible for SMC. This limitation arises due to the need to maintain compatibility with the TCP socket-based API and the constraints of the in-kernel ring buffer used for communication.
To fully unleash the potential of SMC and meet the high bandwidth requirements, we propose a new set of simple APIs built upon the SMC socket API, which we call ERM (Extended Remote Memory). With ERM, users can perform direct read/write operations on remote memories without any memory copying, akin to RDMA, but with much simpler usage. The core benefits of SMC-ERM include:
This talk will introduce the SMC-ERM concept to the community for the first time, covering its design, usage, and performance metrics compared to TCP and RDMA.
Efficient use of the CPU cache is critical for network stacks to demonstrate good performance. However, reasoning about cache usage is hard, as demonstrated by a recent kernel patch [1] that showed how the fast path of the Linux TCP stack had been accessing 50% more cache lines than necessary for several years.
We present CFAR, a tool that enables developers to automatically reason about the cache usage of their own and third-party code. CFAR achieves this using a two-step process. First, CFAR uses automated program analysis to transform the code into an abstract representation (a "distillate") of how the code accesses memory. Then, CFAR allows developers to write simple queries that transform the distillate into answers to specific questions about cache usage. Since the distillate is a precise abstraction of the code’s memory usage (i.e., it contains all the information relevant to how the code accesses memory), developers can use projectors to answer diverse questions about the code’s cache usage.
Our initial results with CFAR are promising. In addition to being able to automatically replicate the results of the patch, CFAR has identified similar inefficient cache access patterns in other kernel-bypass stacks. Finally, as a side benefit, we used CFAR to analyze more than just performance properties related to caches and show how it can be used to identify cache-related leakages in cryptographic code.
[1] - https://lore.kernel.org/netdev/20231129072756.3684495-1-lixiaoyan@google.com/
The Netdev CI has been checking patches sent to the Netdev mailing list for a couple of years now. Thanks to that, Netdev maintainers are able to easily check which patches are causing issues despite the high volume of patches that are shared every day. Until this year, the CI was limited to kernel builds, and various static checks, but the good thing is that all results were already available publicly. Kernel developers can then access the logs to understand what went wrong, without too much assistance from the maintainers.
In 2024, the Netdev CI has seen the introduction of functional tests by running many Network kernel selftests and unit tests. Even if some of these tests were certainly executed regularly by some, they are now automatically tested, and their results are available to all. This really helps Netdev maintainers and contributors to catch regressions early, and encourage everybody to have their new features and fixes covered by new test cases.
This talk will present how the Netdev CI is currently working, and the small details that are important to know. But it will also explain how it can be extended, e.g. to run some tests on real hardware to validate some drivers, to execute other specific tests that are not part of the kernel repo, tracking performance regressions in a dedicated environment, etc.
Another topic that will be mentioned is how Network subsystems, can have a similar service on their side. The MPTCP CI will be taken as an example, using GitHub Actions with KVM support to run various tests on development patches without having to maintain custom servers similar to what is in place with the Netdev CI.
For some time now Cilium ships with a native WireGuard integration in order to
provide a lightweight encrypted tunneling solution in the Cloud Native ecosystem
for K8s Pod traffic and to connect multi/hybrid-cloud environments. It also acts
as an alternative to Cilium's IPsec integration. From a BPF and Cilium point of
view, it provides nice benefits in that WireGuard is i) just another hop on the
virtual wire on the local node, and ii) it is less complex to orchestrate than
alternatives.
We briefly talk about Cilium's WireGuard integration and then the talk focusses
on potential ways to improve its performance. In particular, wireguard-go, a
pure user space implementation of WireGuard was able to surpass the in-kernel
implementation's performance though piggy-backing on UDP GSO and GRO [0]. In this
experiment, we seek to bring similar benefits to its kernel implementation via
GRO and provide an analysis of our results.
[0] https://tailscale.com/blog/more-throughput
The past few years have finally seen an explosion of uptake hitting the internet of lower-latency solutions like fq_codel for many WiFi chips and CAKE - everything from the mass adoption across the WISP market, to middle box ISP solutions like the eBPF & CAKE based LibreQos appearing, to Starlink's efforts to improve their latencies across the board.
Some bugs have accumulated. This talk goes into the state of Bufferbloat fixes worldwide, what is being done to address the known bugs (with the aid of Comcast, NLNET, and Equinix), and of efforts to move the research and deployments forward faster.
Rust is a systems programming language that is making great strides in becoming the next big one in the domain. Rust for Linux is the project adding support for the Rust language to the Linux kernel.
Rust has a key property that makes it very interesting as the second language in the kernel: it guarantees no undefined behavior takes place (as long as unsafe code is sound). This includes no use-after-free mistakes, no double frees, no data races, etc. It also provides other important benefits, such as improved error handling, stricter typing, sum types, pattern matching, privacy, closures, generics, etc.
This microconference intends to cover talks and discussions on both Rust for Linux as well as other non-kernel Rust topics.
Possible Rust for Linux topics:
Possible Rust topics:
rustc improvements, LLVM and Rust, rustc_codegen_gcc, gccrs...).bindgen, Compiler Explorer, Cargo, Clippy, Miri...).Last year was the second edition of the Rust MC and the focus was on presenting and discussing the ongoing efforts by different parties that are using and upstreaming new Rust abstractions and drivers (Using Rust in the binder driver, Block Layer Rust API, Rust in V4L2: a status report and Converting a DRM driver to Rust) as well as those that are improving the ergonomics and tooling around it (Klint: Compile-time Detection of Atomic Context Violations for Kernel Rust Code, pin-init: Solving Address Stability in Rust and Coccinelle for Rust).
Since the MC last year, there has been continued progress from users (e.g. the Android Binder Driver getting closer to upstreaming all its dependencies) as well as new project announcements (e.g. Nova), the first Rust reference driver merged together with its abstractions (the Rust Asix PHY driver), Rust support for new architectures mainlined (LoongArch and arm64)...
Coccinelle is a tool for program matching and transformation, relying on semantic patches, which describe code changes in terms of fragments of source code. Coccinelle for C has been extensively used on the Linux kernel. For the past couple of years we have been developing Coccinelle for Rust. This talk will highlight the main progress that has been made in the past year, with respect to control flow (...), disjunctions, and macros.
Rust is about more than just memory safety: Several language features provide guardrails that help programmers prevent common mistakes. At the same time, they facilitate the creation of APIs that better convey their intent and make it hard to misuse them.
This presentation provides a gentle and beginner-friendly (no Rust knowledge required) introduction to several of these features. Potentially covered features are:
- enums (safe tagged unions): avoid forgetting to handle all cases.
- encapsulation: make it hard to (ab)use implementation details.
- traits: design flexible interfaces and swap implementations without a hassle.
- documentation: leverage markdown directly in the source code to provide useful examples and guidance for API users.
This talk will show how it is possible to write Rust code without a binding layer, with a focus on V4L2 codec drivers and libraries. It will present a strategy wherein only a few critical functions are converted to Rust while accounting for the role of the "cbindgen" tool in keeping ABI compatibility. The source code of a previously submitted proof-of-concept will be used to provide examples.
In this talk we present our efforts on implementing a safe Rust API for the hrtimer subsystem. The API is used for timer based completions in the Rust null block driver.
We discuss application of the "intrusive pattern" first applied in the workqueue Rust abstractions, and other challenges in defining an ergonomic and safe API.
Atomics and memory consistency model are important building blocks for kernel development. Based on a few previous discussions, the current conclusion is to roll our own atomics and memory model (using Linux kernel memory model) for Rust code in kernel. A patchset has been posted, while that patchset evolves in it own way, it'll be great to have an opportunity for status update, feedbacks and future plan discussions, things are planned to cover in this session are:
Birds of a feather
sched_ext is a Linux kernel feature which enables implementing host-wide, safe kernel thread schedulers in BPF, and dynamically loading them at runtime. sched_ext enables safe and rapid iterations of scheduler implementations, thus radically widening the scope of scheduling strategies that can be experimented with and deployed, even in massive and complex production environments.
sched_ext was first sent to the upstream list as an RFC patch set back in November 2022. Since then, the project has evolved a great deal, both technically, as well as in the significant growth of the community of sched_ext users and contributors.
The following are the main topics that will be discussed during the MC:
An update on the current status of sched_ext, initiating discussions about potential future directions, and the growth of the community.
The componentization of the scheduler using a library-oriented approach to /minimize code duplication among the scx schedulers.
Defining a set of APIs for user-space scheduling, including Rust schedulers and Rust/C hybrid schedulers.
Distro integration: addressing challenges and open issues related to shipping sched_ext and scx-based schedulers in Linux distributions.
Practical applications of sched_ext: exploring how sched_ext can be utilized and its benefits in real production environments (e.g., SteamDeck, Meta).
The use of sched_ext in virtualized and para-virtualized environments.
Logistics notes
This is the first time we've proposed a sched_ext MC, so we have no results and accomplishments to discuss from prior meetings
We've discussed the possibility of combining with either the sched or sched-RT microconferences with the authors of those MCs, and we all agree that there are already too many topics to combine the MCs
I'd like to open the sched_ext MC session by:
Giving an overview of the current state of the project. Discussing what features are available, what the current status is upstream, how to access the tree and submit features, etc.
Discussing future directions for the project. What are the existing gaps in the sched_ext framework? What scheduling ideas are possible but not yet explored? How do we expect the sched_ext community to continue to grow?
I don't know exactly how long the talk will be, but I expect 20 mins should be more than enough.
This talk aims to define the appropriate API for a user-space framework that allows to implement sched_ext schedulers.
One significant advantage of a user-space implementation is access to a wide range of debugging and profiling tools, libraries, and services.
Currently, scx_rustland_core is a Rust crate included in the scx git repository, designed to achieve this goal.
The discussion will cover how to better integrate user-space Rust schedulers, Rust hybrid schedulers, and C hybrid schedulers within the same framework.
Igalia has been working to leverage sched_ext support on the SteamDeck, and has been seeing encouraging results. This discussion will allow us to discuss techniques that do and don't work for interactive workload testing, optimizing for gaming workloads, and how to validate interactive scheduler changes.
A look at some of the BPF based policies we've developed that are currently running (or will soon be running), large chunks of Google's infrastructure. The focus of the talk will be on some of the scheduling design choices, how they differ from CFS, and what we've learned along the way. We'll discuss how these changes may inspire CFS or other pluggable schedulers. For example, one key tradeoff we've been able to make is to represent scheduling entities more strongly at the group level, rather than treat everything as independent threads (which CFS must do). This gives better grouping properties for keeping jobs constrained on shared server environment.
Applications running inside a virtual machine experience dual level of task scheduling i.e. the Guest scheduler decides how to place application threads on the vCPUs, and the Host scheduler decides how to place the vCPU threads on the pCPUs. Neither the Guest nor the Host scheduler has the complete information to make optimal task placement decisions across both the levels. This leads to various known issues like the Lock Holder Preemption problem, the Blocked Waiter Wake-up problem, the RCU Reader Preemption problem, the problem of the Guest scheduler being oblivious to the runtime changes to vNUMA on the Host, the problem of delayed IO in the Guest, etc.
The root cause of these problems is the semantic gap between the decisions made by the Host and the Guest schedulers. Many academic as well as in-kernel solutions demonstrate that the semantic gap can be addressed efficiently by para-virtualizing the scheduling related information between the Host and the Guest. This talk discusses about the technical challenges encountered in the endeavour of aggregating and using para-virtualized scheduling information with the sched_ext schedulers.
Unbeknownst to the upstream Linux community, there exists a variety of alternative Linux CPU schedulers, circulating downstream for years.
The CachyOS Linux distribution, an Arch Linux derivative founded in May 2021, has painstakingly collected these patches into a nicely organized repository, bringing them to the fruition of a larger audience. The project itself derived its name from one of these schedulers, Cachy by Hamad Salim Al Marri; the Cachy scheduler has later been renamed to CacULE. Some of the most popular schedulers currently in circulation are:
The goals for this session are to illustrate the algorithms employed by these schedulers, bring them to the attention of the wider upstream kernel community, and explore the opportunity to implement them using the sched-ext framework to allow for an even wider circulation of their underpinning ideas.
The CachyOS Linux distribution is sched-ext best friend! We're a young distro, a passion project born in mid 2021, focused on delivering a solid and performant desktop experience. As early adopters of sched-ext (we started shipping it in December 2023), we've learned some important lessons from the experience with our user base that we'd like to share with the community at large.
Integration of custom schedulers such as Rustland and LAVD with the OS as a whole is the aspect we've learned the most about. We'll describe the systemd services we've written to manage schedulers, the challenges we encountered along the way and what our solution has been. On an adjacent note, user-space schedulers such as Rustland are very "chatty" (produce a high volume of diagnostic information), and managing all that data with journald logs wasn't obvious. In our experience, system upgrades also need to be handled with care when custom schedulers are in use; our package manager (pacman) supports custom hooks, which we decided were the appropriate tool to employ. We'll describe our solutions, but most of all, we'd like to know if there's any obvious alternative that we overlook, and overall get some feedback from an audience that likely has been doing this for a lot longer than us.
Lastly, we'll share what our users told us about these enhancements. We're heavily involved with our community, via our Discord server, Telegram channel and Discourse forum. They helped us and the sched-ext developers identify and fix tons of bugs very early, and suggested a few improvements that we'll be reviewing.
Please join us for this session, we have gained lots of experience on what it means to choose a specialized scheduler depending on the activity you do on your machine, and we can't wait to share it.
What are the benefits and concerns from the standpoint of distros regarding sched-ext and pluggable schedulers? Are there any roadblocks on the path to making packages available to users?
This session is a venue for distro maintainers to share experiences, discuss issues and review plans related to the enablement of sched-ext downstream.
A non-exhaustive list of topics to cover:
The System Boot and Security Microconference has been a critical platform for enthusiasts and professionals working on firmware, bootloaders, system boot, and security. This year, the conference focuses on the challenges that arise when upstreaming boot process improvements to Linux kernel. Cryptography, which is an ever evolving field, poses unique demands on secure elements and TPMs as newer algorithms are introduced and older ones are deprecated. Additionally, new hardware architectures with DRTM capabilities, such as ARM's D-RTM specification, and the increased use of fTPMs in innovative applications, add to the complexity of the task. This is the fifth time in the last six years that the conference is being held.
Trusted Platform Modules (TPMs) for encrypting disks have become widespread across various distributions. This highlights the vital role that TPMs play in ensuring platform security. As the field of confidential computing continues to grow, virtual machine firmware must evolve to meet end-users demands, and Linux would have to leverage exposed capabilities to provide relevant security properties. Mechanisms like UEFI Secure Boot that were once limited to OEMs now empower end-users. The System Boot and Security Microconference aims to address these challenges collaboratively and transparently. We welcome talks on the following technologies that can help achieve this goal.
If you want to participate in this microconference and have ideas to share, please use the Call for Proposals (CFP) process. Your submissions should focus on new advancements, innovations, and solutions related to firmware, bootloader, and operating system development. It's essential to explain clearly what will be discussed, why and what outcomes you expect from the discussion.
P.S. We can only make it on September 18 because of conflict with other event.
The presentation highlights five challenging areas and activities to address those in various communities over the last two years.
The topics will be considered in the context of other presentations planned for the 2024 edition of System Boot and Security MC.
We would like to propose a new boot-firmware repository similar to the Linux-firmware repository under the aegis of U-Boot hosting.
In addition to TI [1], it looks like many SoCs (see NXP[2] and Rockchip[3] eg.:) platforms seem to require additional closed-source/open-source binaries to have a complete bootable image. Distribution rights and locations of these binaries are challenging, and there needs to be a standard for how and where they are hosted for end users.
Further, looking ahead to future architectures, we see at least 3 category of firmwares:
Proposal is to create a boot firmware repository in Denx and/or GitHub (if financials are a hurdle, I hope we can solve it as a community).
Also define scope of the repo: what type of firmware can be hosted, licensing, size limit?, what about open source firmwares?, Workflow, ABI and integration guidelines?
Initial RFC on U-Boot list has more details and early feedback of U-Boot community members [4]
[1] https://docs.u-boot.org/en/latest/board/ti/k3.html#software-sources
[2] https://docs.nxp.com/bundle/AN14093/page/topics/build_the_u-boot.html
[3] https://bbs.t-firefly.com/forum.php?mod=viewthread&tid=2236
[4] https://lore.kernel.org/u-boot/20240620213539.ftmjhphypssxp5n4@desolate/
Regards
Vignesh / Nishanth
The Linux kernel has been observed to take several 10s of seconds to boot-up on machines with many CPUs (~1792 CPUs). This talk delves into the details of bottlenecks uncovered in the CPU online path when testing on large NUMA multi-core virtual machines and outlines some of the fixes that helped achieve up to 50% faster boot times on such VMs. These optimizations range from approaches such as amortizing the cost of certain repetitive calculations by deferring them until all CPUs are up [1], to rewriting CPU hotplug callbacks as worker functions and leveraging the kworker infrastructure to run these callbacks in parallel on all the online CPUs.
Further, this talk will draw focus on the internals of the CPU hotplug framework, whose callback invocation is still primarily sequential and executes them one after another on a single CPU, irrespective of how many CPUs are already online (and thus readily available for parallel execution). This design gets particularly expensive for those CPU online callbacks whose computation involves loops (or nested loops with NUMA nodes) that span every online CPU. As a result, the current design incurs a linear degradation (or worse) in the execution time for such callbacks as the number of CPUs (and NUMA nodes) grows, thus making each CPU online operation progressively slow as the Linux kernel makes its way through the boot-up sequence.
We will discuss approaches to address these issues to scale booting and CPU online operations for large multi-core systems and seek to brainstorm with the community and get their invaluable feedback.
References:
[1]. [PATCH] mm/vmstat: Defer the refresh_zone_stat_thresholds after all CPUs bringup - Saurabh Sengar (kernel.org)
https://lore.kernel.org/all/1720169301-21002-1-git-send-email-ssengar@linux.microsoft.com/
at first i want to give a brief description of what SBAT is, why it was implemented and what currently supports it ( grub2, shim, systemd-boot various EFI tools, like fwupdate and etc ).
And also cover that SBAT expects different downstream distros to adopt upstream SBAT values from the code base they consume, so that a proper revocation by SBAT is always ensured.
And explain why SBAT revocation is even needed in the first place instead of revocation by adding a certificate to a DBX.
It is just my experience that SBAT is still a very much grey area for many developers and enterprise users.
Second - i want to cover the scenario of preventing locking yourself down, when you update components de-synced, i.e. new shim is issued with a new grub2, but users decide to install only a new shim, and may end up in locked down system, i want to highlight the fact, that since boot chain is a system critical sub-system, it makes sense to introduce a dependency mechanism that ensures a correct set of packages is being pulled in. In many distros right now it is being ensured simply by “install all updates”, but you may end up in a scenario of being unable to boot if you decide to pursue limited package set installation ( that happens often if distros are pulling in only packages with “CVE fixes” ).
Third - i want to cover use case of rolling back to older SBAT “level” in case it is needed in specific production environments. Mainly it will be about how to design your deployment/system so that you do NOT end up locked down, and can prepare in advance for such potential rollback. Instead of just disabling SBAT, in fact a proper design scheme of SBAT levels should be implemented, and trigger events to move from one level to another should be in place.
Fourth - i will be covering scenario of locking yourself down in case of using several distributions on same system due to SBAT update and what is a proper mechanism of getting yourself unlocked and preventing such scenarios.
U-boot is commonly used to provide a UEFI environment on embedded platforms, making it easier to run commodity operating systems. But what about the inverse case, where we want to make a commodity platform look more like an embedded one? U-boot has a less well known feature for being used as a UEFI payload, but it has poor support for generic hardware and doesn't interact well with runtime UEFI support. This presentation will describe work done to make this functionality more generally usable, and also explain why anyone would want this at all in the first place.
We are working on a new scheme to replace the GRUB boot loader with a fast, secure, Linux-based, user-space solution: nmbl (for no more boot loader).
GRUB is a powerful, flexible, fully-featured boot loader used on multiple architectures, but its features create complexity that is difficult to maintain, and that both duplicate and lag behind the Linux kernel while also creating numerous security holes. On the other hand, the Linux kernel, which has a large developer base, benefits from fast feature development, quick responses to vulnerabilities and greater overall scrutiny.
Our solution is to use the Linux kernel as its own boot loader. Loaded by the EFI stub on UEFI, and packed into a signed unified kernel image (UKI), the kernel, initramfs, and kernel command line contain everything they need to reach the final boot target. All necessary drivers, filesystem support, and networking are already built in and code duplication is avoided.
We will discuss the work done so far, as well as challenges and future plans, and would be grateful for your feedback and use cases.
Given the present discussions around UKI and nmbl, Linux appears to be headed towards a future where it most commonly boots directly rather than via a separate bootloader. The IBM Linux on Power team agrees that this is a laudable direction: work need not be duplicated between the kernel and bootloaders and the entire class of bootloader-specific bugs - including vulnerabilities - would become simply Linux bugs. Currently, community efforts appears to be focused on UEFI-based platforms but other platforms like OF are omitted. Security is an important factor to consider across platforms because it will be affected by changes in the boot sequence. This brief talk outlines some points for consideration when directly booting Linux on OF-based Power systems and calls for the inclusion of non-UEFI platforms in next generation boot designs.
systemd has gained various TPM-related components in the recent past, to make measured boot on generic Linux reality.
In this talk I'd like to shed some light on recent developments in this area, and what comes next. Some of the topics touched will (probably) be:
TrenchBoot is an OSS project that is used to establish the integrity of the loaded software. The previous work was focused on Intel and AMD implementations of their dynamic root of trust mechanisms. Arm, in consultation with members of the TrenchBoot community, designed a DRTM implementation for their platform. This presentation focuses on the initial design work to bring Arm support to the TrenchBoot Secure Launch solution.
BOLT (Binary Optimization and Layout Tool) is an open-source post-link optimizer with a proven record of improving CPU performance in data-center applications. Even on top of traditional compiler PGO and LTO techniques, applying BOLT results in double-digit CPU load reduction.
Recently, we added Linux kernel support to BOLT and tested the optimized kernel on large-scale production workloads with positive performance impact.
After a brief introduction to post-link time optimizations, this talk will cover the challenges BOLT had to overcome to become a practical tool for optimizing the kernel. We’ll also present BOLT “deep-scan” disassembly, a tool that can reveal information about the Linux kernel otherwise unavailable to classic disassemblers like objdump, such as static calls/keys.
The talk will conclude with a demo of BOLT and deep-scan disassembly on a typical vmlinux binary.
We would like to make a data-driven case to integrate AutoFDO support into the Linux kernel. AutoFDO is a profile guided optimization technique that uses hardware sampling to optimize binaries. Compared to Instrumentation based FDO (iFDO), AutoFDO is significantly more user-friendly and straightforward to apply. While iFDO typically yields better profile quality and hence more performance than AutoFDO, our results demonstrate that AutoFDO achieves a remarkable level of effectiveness, bringing the performance close to iFDO in optimizing benchmark applications.
In this proposal, we'd present performance improvements from optimizing the kernel with FDO, both via hardware sampling (AutoFDO) and instrumentation (iFDO), on micro-benchmarks and large warehouse scale applications. Our data makes a strong case for the inclusion of AutoFDO as a supported feature in the upstream kernel.
Furthermore, other advanced compiler optimization techniques, including ThinLTO and Propeller can be stacked on top of AutoFDO. We have experimented with AutoFDO combined with ThinLTO and Propeller, we'd also like to present these numbers.
We have posted our experiments and numbers on the llvm forum.
Another year of work is behind us, with lots of progress across GCC, Clang, and Rust to provide the Linux kernel with a variety of security features. Let's review and discuss where we are with parity between toolchains, approaches to solving open problems, and exploring new features.
Parity reached since last year:
counted_by attribute for bounded Flexible Array Members (GCC, Clang)In progress:
-fbounds-safety language extension (Clang)-fsanitize=(un)signed-integer-overflow, -fsanitize=implicit-(un)signed-integer-truncation, and idiom exclusions (Clang)-Warray-bounds warnings (GCC)Stalled, needs driving:
This talk presents the status of the three current binary front-ends supported by Libabigail tools for ABI analysis: DWARF, CTF, and BTF.
The talk explores their features, the overall architecture that allows these front-ends to co-exist and the path to their further improvement.
The talk also presents the current state of the overall project as well as the development areas that are currently being envisioned.
Please note that the talk is an interactive session where participants are invited to raise issues they are facing in the realm of ABI analysis so that we can come up with ideas to address them.
In this activity we will first provide a very brief update on the status of the port of GNU binutils and GCC to the BPF target, with special emphasis on the level of support for extant BPF programs and the kernel BPF selftests. Then we will address a set of particular issues for which we need feedback from the BPF kernel hackers.
We are extending the CTF type format (in the GNU toolchain for several years now) by making its next file format version a superset of BTF, with the option to emit straight BTF as well; this means that the existing toolchain machinery (generation with GCC, deduplication and linking with GNU ld, reading and writing with libctf) will start working with BTF as well. (It will remain capable of generating CTF for any target, not only BPF.)
This means that we could integrate this into the kernel build process and both free pahole from the need to deduplicate BTF and also remove the need to generate DWARF at build time, speeding up builds.
libctf has some extra features that may be useful for the kernel's BTF generation process: it can deduplicate all in-tree modules and core kernel BTF against each other and store them in a fast-to-access, compact archive (entire enterprise kernels including all modules fit in 16MiB); it can identify and represent types with conflicting definitions; it can reliably detect incompatible parent containers so as to refuse to import them; and it can represent the various static-scope and global-scope variables found in kallsyms.
This activity introduces this machinery and asks for opinions on how (and if) to improve it with a view to integrating it into the kernel build process.
The availability of BPF and various other tracing features in the kernel, along with upcoming features, make it possible to be very creative. Higher level tracing tools like DTrace can combine the available probes and probing mechanisms to present users with semantic probes that hide the ugly implementation details that are often quite kernel release specific.
This is especially significant during development and in terms of interactions with the toolchain to maximize functionality and ease-of-use.
The talk will describe some of the techniques (as used in DTrace, but applicable to other tracing tools as well), the pitfalls, failed attempts, and success stories. The main focus is on the technical aspects, with a view on future developments and hoped-for features that could make this even more powerful.
Feedback and suggestions from the participants are welcome and encouraged.
In its simplest cases, building a kernel requires very few dependencies and can be done with a couple of make commands. However, things can get complicated very quickly: fine-tuned toolchains such as the kernel.org ones provide a wide variety to choose from, each compiler has a particular supported version range, eBPF kselftests require a cutting-edge LLVM, the Rust code is still tied to the latest rustc compiler releases...
How can contributors find out maintainers' recommended ways to build a kernel? How can test systems determine the best way to reach optimal build coverage? How should a kernel be built to reliably reproduce a known issue? These things can be very error-prone without a structured description of the build environment.
Following an email discussion[1] on this topic, several ideas have already been brought up and a live session at Plumbers would help pave the way to reach a true upstream solution. In particular:
Many steps have already been made in this direction by various independent parties. The proposal is now to try and consolidate this as a first-party solution for the upstream kernel, as per the quote below.
On 09/07/2024 07:30, Nathan Chancellor wrote:
I think it would be a good idea to try and solicit feedback from the
greater kernel community at large to ensure that whatever solution is
decided on will work for both testing systems and
developers/maintainers. I think that a first party solution for having a
consistent and easy to set up/work with build environment has been
needed for some time but unfortunately, I am not sure how much
discussion around this problem has happened directly with those folks.
[1] https://lore.kernel.org/all/f80acb84-1d98-44d3-84b7-d976de77d8ce@gtucker.io/
Remote Build Execution (RBE) technology is starting to gain traction among organizations which maintain large codebases as a means of speeding up builds and reducing their infrastructure costs. Originally developed around the Bazel build system, it has since been adopted by other code bases, for example Chromium and AOSP. This talk will explain how RBE works, how it can be applied to the Linux kernel, and provide a list of open-source backends that organizations and maintainers can deploy on their own infrastructure.
The PCI interconnect specification, the devices that implement it, and the system IOMMUs that provide memory and access control to them are nowadays a de-facto standard for connecting high-speed components, incorporating more and more features such as:
These features are aimed at high-performance systems, server and desktop computing, embedded and SoC platforms, virtualisation, and ubiquitous IoT devices.
The kernel code that enables these new system features focuses on coordination between the PCI devices, the IOMMUs they are connected to, and the VFIO layer used to manage them (for userspace access and device passthrough) with related kernel interfaces and userspace APIs to be designed in-sync and in a clean way for all three sub-systems.
The VFIO/IOMMU/PCI MC focuses on the kernel code that enables these new system features, often requiring coordination between the VFIO, IOMMU and PCI sub-systems.
Following the success of LPC 2017, 2019, 2020, 2021, 2022, and 2023 VFIO/IOMMU/PCI MC, the Linux Plumbers Conference 2024 VFIO/IOMMU/PCI track will focus on promoting discussions on the PCI core and current kernel patches aimed at VFIO/IOMMU/PCI subsystems. Specific sessions will target discussions requiring coordination between the three subsystems.
See the following video recordings from 2023: LPC 2023 - VFIO/IOMMU/PCI MC.
Older recordings can be accessed through our official YouTube channel at @linux-pci and the archived LPC 2017 VFIO/IOMMU/PCI MC web page at Linux Plumbers Conference 2017, where the audio recordings from the MC track and links to presentation materials are available.
The tentative schedule will provide an update on the current state of VFIO/IOMMU/PCI kernel sub-systems, followed by a discussion of current issues in the proposed topics.
The following was a result of last year's successful Linux Plumbers MC:
Tentative topics that are under consideration for this year include (but are not limited to):
PCI
If you are interested in participating in this MC and have topics to propose, please use the Call for Proposals (CfP) process. More topics might be added based on CfP for this MC.
Otherwise, join us in discussing how to help Linux keep up with the new features added to the PCI interconnect specification. We hope to see you there!
Key Attendees:
Contacts:
Key takeaway - interrupts are what makes this complex.
The PCIe port driver is an unusual beast:
- It binds to several Class Codes because they happen to have common features. (PCI Bridges of various types, Root Complex Event Collectors).
- It then gets ready to register a set of service drivers.
- Before registering those service drivers it has to figure out what interrupts are in use which requires per service driver code (so as not to use more interrupt vectors than necessary). An enable lots, check usage and shrink dance occurs.
- The available services are all baked in - the modularity is largely an illusion.
New features are being implemented in PCIe switches and Root Ports. These are enumerable via config space + BARs (VSEC / DVSEC / PCI 6.2 MCAP) Today three approaches exist to add support:
- If they need interrupts, they have to be a portdrv service (e.g. CXL Performance Monitoring Units)
- If they don't use interrupts, then a parallel search and registration infrastructure can be used (CXL ports / HDM decoders, Designware RP PMUs) - however this creates non obvious life time issues for switch ports which may be hot removed.
- Support only in the PCIe core - no interrupt possible (CMA for device attestation, interrupts would be nice!).
A number of discussions have taken place on the mailing list (most recently https://lore.kernel.org/linux-pci/20240605180409.GA520888@bhelgaas/ ) and in previous LPC corridor tracks.
The potential paths forward are:
1) Admit we are stuck with basic concept of portdrv. Work out how to make it extensible.
2) Push all the current service drivers (AER, DPC etc) into the PCI core and deal with interrupts (either dynamic MSI-X or quiescing to resize or just allocate N and assume enough!). Then support additional features via standard PCI drivers on top. (This runs into some snags due to devres)
The aim of this session is to first seek agreement on the requirements and then how they align with the possible options.
Early prototypes will hopefully identify additional open questions before LPC.
PCIe Bandwidth Controller (bwctrl) is a PCIe portdrv service that allows controlling the PCIe Link Speed for thermal and power consumption reasons. The Link Speed control is provided through an in-kernel API and for userspace through a thermal cooling device. With the advent of PCIe gen6, also the PCIe Link Width will become controllable in the near future.
On PCIe side, bwctrl requires full control over the Link Bandwidth Management Status (LBMS) bit. There is pre-existing use of the LBMS bit in the kernel by the Target Speed quirk. The quirk also requires altering PCIe Link Speeds when the quirk activates which should use the newly introduced in-kernel API. As such, bwctrl comes with integration challenges related not only to the use of LBMS bit but also what parts of bwctrl have to be always built to allow the Target Speed quirk to keep working.
We encountered a performance bottleneck while testing NCCL on a GPU cluster with 8x H100 GPUs and 8x 400G NIC nodes. Despite a theoretical capacity of 400 Gb/s, our system consistently reached only ~85 Gb/s. The primary issue was identified as communication constraints between GPUs and NICs under the same PCIe switch.
This session will concisely overview the challenges we experienced, such as the PCIe switch and NIC firmware issue, full test results, and solutions we explored to achieve ~390 Gb/s. Furthermore, we will focus on the root cause related to IOVA to HPA translation, evaluating the potential solutions we tried: Address Translation Services (ATS) and IOMMU regrouping.
We would like to hear comments on the pros and cons from the kernel and vendor experts and discuss further to find a better solution.
A brief iommufd update and time for any active discussion that needs resolution.
A discussion on Generic Page Table which should reach the mailing list as RFC before the conference. Generic Page Table consolidates the page table code in the iommu layer into something more like the MM with common algorithms and thin arch specific helpers. Common alogrithms will allow implementing new ops to solve some of the open problems people have.
PPC64 implementation of VFIO is spread across two vastly different machine types (pSeries, PowerNV) trying to share a lot of common code driven by PPC specific SPAPR IOMMU API.
The support of the PCI device assignment on these sub arch's have gone through many cycles of breakages and fixes with ongoing efforts to add support for IOMMUFD, which PPC64 is yet to catch up to. Enhancements[1] to bring consistency to the SPAPR IOMMU management for both the machine types exposed quite a few challanges due to underlying arch differences and the way VFIO and IOMMUFD models containers. One of the key departure from earlier attempts at VFIO support was to move away from "borrowing" the DMA window which limited the customization of the window size.
The talk aims the below,
References:
[1] - https://lore.kernel.org/linuxppc-dev/171810893836.1721.2640631616827396553.stgit@linux.ibm.com/
Live update is a mechanism to support updating a hypervisor in a way that has limited impact to running virtual machines. This is done by pausing/serialising running VMs, kexec-ing into a new kernel, starting new VMM processes and then deserialising/resuming the VMs so that they continue running from where they were. When the VMs have DMA devices assigned to them, the IOMMU state and page tables needs to be persisted so that DMA transactions can continue across kexec.
In this session we want to discuss a revised approach to solving this problem: introducing persistent iommufd IOAS and HW pagetable. The idea is to use the Kexec Hand Over (KHO) framework as a mechanism to pass the persisted data across kexec and to restore it after kexec: https://lore.kernel.org/kexec/20231213000452.88295-1-graf@amazon.com/
We'd like to have a discussion about what the correct abstraction is for marking IOMMU(FD) domains as persistent, setting up persistent mapping and discovering and restoring the domains after kexec.
RFC patches will be posted before hand to make the problem clearer.
This session will be iterating on the live update concept which was discussed at last LPC, and it will be an revision to the idea of pkernfs which was floated as a potential solution: https://lore.kernel.org/all/20240205174238.GC31743@ziepe.ca/
The PCI ATS Extended Capability allows peripheral devices to participate in the
caching of translations when operating under an IOMMU. Further, the ATS Page
Request Interface (PRI) Extension allows devices to handle missing mappings.
Currently, PRI is mainly used in the context of Shared Virtual Addressing,
requiring support for the Process Address Space Identifier (PASID) capability,
but other use cases such as enabling user-space driver driven device
verification and reducing memory pinning exists. In this talk we describe how
IOMMUFD may be extended in a non-SVA and non-nested context to enable user space
processes to handle page requests from VFIO PCI attached devices.
We describe our proposed changes to IOMMUFD and present a user space reference
implementation within the libvfn library. In combination with QEMU ATS/PRI
emulation, this functionality enables use-case experimentation,
hardware/software co-design and device verification for these features. We
examine in detail how ATS/PRI is tested, offering insights into the potential of
using user space testing frameworks in device validation methodologies.
Platform devices are those that are discovered via something like a device-tree.
Once discovered, the device is typically available for the life of a VM. IOW
platform devices can't be hotplugged in its typical sense. Qualcomm however is
having usecases where platform device ownership need to be managed at runtime
between VMs. A VM that has ownership of a platform device is required to
temporarily pass ownership of the device to another VM. An example of this is
display and touch screen. Applications like mobile banking handle sensitive
information like password obtained from user via touch screen. It may be
desirable to have a confidential VM processing such sensitive information. That
would require the confidential VM to temporarily gain ownership of touch screen
and display from the main OS.
How can this transfer of ownership for platform devices be best accomplished by
Linux? One naive option is to unload/load drivers or unbind/bind the device from
its native driver, which however leads to increased latency and in some cases
may not be even possible (given dependent drivers). Other option is for platform
drivers on both OS to synchronize access to device, so that a driver in one OS
"stops" accessing device while its "in use" by driver in other OS. The
hypervisor would ensure that an erring VM gets a fault when it tries to access a
device after having relinquished ownership.
Rather than relying on individual platform drivers to synchronize on this
ownership transfer, can the platform bus driver (on receiving VM side) and VFIO
platform driver (on host side) provide a generic mechanism here?
Also what mechanism can the IOMMU driver use to transfer
ownership? For example, hypervisor would need to recognize the ownership
transfer of a platform device using particular SID (stream ID) by switching to
use of different translations tables for transactions related to that device.
As a follow up to the last year's 'PCI Endpoint Open Items Discussion', below are the topics for discussion this year:
At Plumbers 2023 we held a build systems microconference to provide a place for people interested in build Linux Distributions to discuss the common problems they face. Based on the success of the 2023 microconference, we would like to have another microconference in Vienna. Last year, people discussed, supply chain security, kernel management, user api compatibility, and patch tracking. Each topic generated good discussions and we would like to continue the conversation this year.
The intended audience is anyone building Linux distributions. We would love participation from the Debian, Fedora, Red Hat, Nixos, Buildstream, Buildroot, OpenEmbedded, Yocto Project and other communities with a shared interest in building and maintaining Linux Distributions.
The organizers introduce themselves and set expectations
AOSP is a Linux operating system for smart phones, tablets, TVs and many other sorts of device, all of which fall under the broad term "embedded". AOSP has it's own build system, but it shares many characteristics with others. Initially it was based on GNU Make (Buildroot-like), then with Android 8 it began the migration to a new tool called Soong, with recipes written in a format called Blueprint. Soong and Blueprint have a lot in common with OpenEmbedded and Bitbake. Since Android 8, the migration to Soong has stalled, maybe because of the effort that would be required to move all logic from Makefiles to Soong modules and Blueprint
I want to explore the consequences of depending on a single-purpose build system and how AOSP has reacted to the challenges over the years. Points for discussion:
Both for security and for license compliance, we need to be able to trace which software (source code) goes into the artefacts we produce. Buildroot and Yocto build systems produce a bill of materials, but is this sufficient? Let's discuss some of the shortcomings and how we can deal with them.
As the landscape of operating systems continues to diversify, there is a growing
interest in running multiple operating systems and applications, each with
different capabilities and functionalities, on a single device.
However, how may these applications or operating systems vary from one another?
The C library plays a crucial role in this. Having the flexibility to choose one
C library over another (or none at all) provides a significant design benefit
that is sometimes downplayed. This is the motivation behind recently integrating
picolibc as a possible C library for systems built using OpenEmbedded.
This topic would fuel discussions on the approaches used or considered by build
systems for providing different C libraries and the importance of providing
flexibility, while exploring the implementation used by the OpenEmbedded
ecosystem, which is now capable of cross-compiling applications using glibc,
musl, newlib, and picolibc.
We recognize Open Source Software as one of humanity's greatest tools for aggregating and disseminating reusable functionality. This supports a dualistic view where individual needs are met while the greater good is altruistically served.
As effective as Open Source Software is at serving its dualistic nature, there is still a tension between the needs of build integrators, who value stability and consistency, and those of projects that are motivated by the progression of features. Nowhere is this more apparent than in the discipline of Safety Engineering.
Using Open Source components in a safety-critical context requires a significant investment. In the vast majority of situations, this investment is so high that it precludes the ability to track upstream changes. Additionally, the safety-critical niches where Open Source software finds itself makes it virtually impossible to effectively communicate change back to the upstream community. Even as proprietary barriers fall away, upstream projects have little interest in patches developed against older versions.
What is missing is a systematic understanding of the value that Safety Engineering brings to the table in the form of design rigor and its approach to testing. Embracing this rigor will improve software quality as much as the embrace of Security Engineering has improved software quality over the last 30 years. At the same time, incorporating these techniques will enable integrators to more effectively use Open Source components in safety-critical contexts and transmit beneficial change back upstream.
In this talk, Chuck will succinctly describe the Open Source duality, the tension between build integrators and individual projects, the benefits of Safety Engineering's approach to testing and design rigor, and lay out a vision and a roadmap for gaining the Open Source community's confidence in the value of these techniques.
A thriving ecosystem is crucial for every kind of programming language or environment, and a large portion of it is the "batteries included" mindset, respectively reducing the friction of adding libraries.
Enter APMs - Application Package Managers.
From the distribution building point of view, this is a major problem. Reinvented processes time and again, reproducibility blockers, conflicting version dependencies, and many more sources of joy.
This does not propose any solution, because I don't know of one. Lets raise awareness for this, and hopefully gather some approaches so not everybody needs to figure it out in isolation.
The Yocto project is a toolkit for creating custom Linux distributions for the embedded use cases. Historically it has not provided tools and standards for setting up and replicating build configurations in a reproducible manner, leaving that to third party projects and custom scripts. In the past few months this has been changing, and many of the pieces are now available out of the box in oe-core/poky, or are under review. This talk will give an overview of what is available and how it can be used to both write a record of how to build a complete system, and to replicate that build elsewhere with that record. It will also cover parts that still need to be added, and possible future directions for build configuration management.
The Graphics & DRM Microconference welcomes the community to discuss topics around the Linux graphics stack and the DRM subsystem, with the goal of solving long standing and complex problems together.
The MC CfP is open to all proposals related to graphics, including the following potential topics:
MC Leads:
- André Almeida
- Daniel Stone
Everybody seemingly needs CI and a lot of subsystems already have their spin of
CI running, but everyone is cooking their soup, while when we look at it
the majority of what the CI systems do is very, very similar.
This proposal aims to highlight the different attempts currently floating
around (DRM CI, MediaCI, KCI-Gitlab, CKI, Intel XE, etc.), depicting the
large overlaps but also the differences to start a discussion
about unifying our work in this area.
We are trying to highlight why a joined approach is beneficial to everyone and
helps a new subsystem to get up to speed quickly and which steps are necessary
for the DRM subsystem and why there is no reason to be afraid.
While MIPI DSI bus and MIPI devices has been supported in Linux kernel for quite a while, during the last few years several important corner cases were identified, which make it hard to fit the MIPI DSI devices into the standard DRM pre-enable / enable / disable / post-disable model. Some of the shortcomings were solved via the pre_enable_prev_first call, other shortcomings remain unsolvd. This session describes a proposed solutions for the MIPI DSI drivers model.
Traditional DRM pipelines for embedded devices have no removable components, while PC-style pipelines have long time supported hotplug of the panel only, via standardized connectors such as HDMI or DisplayPort.
Embedded devices being currently developed by the industry have a video pipeline whose last components, including one or more bridges, are located on a hot-pluggable add-on using a non-hotplug video bus (MIPI DSI, LVDS, parallel). On the device we are working on, the "main" board ends at a custom connector where MIPI DSI signals are present, while the add-on has a DSI-to-LVDS bridge and a LVDS panel.
A proposal as been made to add a "hotplug DRM bridge" [Ceresoli 2024 v4] to decouple the fixed and the removable parts of the pipeline so that existing drivers can work transparently with no changes.
The latest discussion is in the v2 thread [Vetter 2024] and already led to improvements in v3 and v4, but there is a lot more work to do and development directions are still to be clarified.
Topics to discuss include:
GPU resets are a common problem for every vendor, due to the nature of the stack. A bad shader can put the render node in an infinite loop, and we need to reset the GPU, partially or completely. However, each driver (both at userspace and kernelspace) have different ideas of what to do when a reset happens.
The goal of this session is to try to find a better common ground of how to manage such resets and how to test this part of the driver.
An initial work on that topic can be find documented here: https://docs.kernel.org/gpu/drm-uapi.html#device-reset
Kernel supports default cma and system dmabuf heaps. In order to support protected usecase, additional heap types needs to be supported.
There are quite a few downstream dmabuf heaps maintained by vendors to support protected usecase. There is need to provide generic framework, which will reduce fragmentation of such dmabuf heap types.
The proposed restricted dmabuf heaps will support different allocation method ( SG, CMA etc) and access restriction methods.
This is a open slot that can be used if the MC contributors wants more time to work together in some topic
The scheduler is at the core of Linux performance. With different topologies and workloads, giving the user the best experience possible is challenging, from low latency to high throughput and from small power-constrained devices to HPC.
The following accomplishments have been made as a result of last year’s micro-conference:
Ideas of topics to be discussed include (but are not limited to):
It is fine if you have a new topic not on the list. People are encouraged to submit any topic related to real-time and scheduling.
The goal is to discuss open problems, preferably with patch set submissions already in discussion on LKML. The presentations are concise, and the central portion of the time should be given to the debate – thus, the importance of having an open and relevant problem with people in the community engaged in the solution.
In virtualized environments, information about the underlying physical CPU topology is usually hidden from the guest systems.
This talk will discuss challenges in scheduling virtual CPUs and how passing topology insights to the guests can be utilized to allow the guests to cooperate and gain performance benefits.
As an example, the s390 architecture will be used to demonstrate how smart choices in this area can contribute to increased performance.
CPU capacity is a software construct to reflect underlying physical CPU capacity. Load balancer uses the CPU capacity to choose an optimal CPU for performance and energy efficiency. CPU Capacity can be affected by frequency, higher level sched classes, guest preemption etc. Steal time is an indicator of guest preemption by the host hypervisor. Current Linux scheduler, updates the CPU capacity based on the steal time.
In IBM powerpc, PowerVM hypervisor schedules at the SMT8 core level, but not at individual thread level and steal time is uniform across the cores. In an overcommitted and overutilized shared environment such as multiple Shared Processor Logical PARrtitions (SPLPAR) it would be optimal to schedule the tasks on limited set of cores instead of spreading across all the cores. Number of cores to schedule can be derived from the percentage of steal time. If the steal time is more, reduce the number of cores which have high capacity and vice versa.
In this talk, we would like to talk about, why current mechanism of updating CPU capacity doesn’t work in the above use case and why we need a different way of updating the CPU capacities by steal time in the paravirtualized environment for effective usage of CPU resources among the guests. We would discuss advantages and disadvantages of different approaches considered such as cgroup cpuset, cpu offline etc. We would discuss the issues present currently, when capacity values are very far reaching such as 1024 vs 1.
One of the bottlenecks to making progress in scheduler is understanding 'what is the problem?'
Reporters who don't understand the scheduler can't provide useful info to help root cause why they see a problem.
Developers, seasoned or new, can trip over many details and corner cases that might make what appears to be a bug to be actually a feature that is just not well understood by the developer.
Using bare tracepoints we can start adding more probing points to understand why wakeup path and load balancer (the most complex parts) have made a decision at a specific point of time. But we don't want to stop there, but solving these two should pave the path to do more.
The difficulty is then on how to we extract this info and present it in a way that is easy to visualize and debug?
sched-analyzer [1] aims to solve this by hooking into mature existing technologies
It is a glue logic that uses bpf and ftrace to connect to the tracepoints and extract whatever info deemed useful and emit them out as perfetto event - which has a mature visualization and sql based query to help understand what a scheduler is doing at any point of time.
It also has a python pandas interface that is combined with its sql query can enable creating strong post processing analysis tools to identify patterns and problems from a captured trace.
sched-analyzer has a TUI based interface that should make sharing output easy on the list.
The main goal of the discussion is to explore ways to introduce better debugging. With sched-analyzer as a potential tool to build on top.
[1] https://github.com/qais-yousef/sched-analyzer
Throttling-like mechanisms such as CFS bandwidth control, extremely biased cgroup CPU shares and CPU masks can create quasi priorities among CFS tasks, and we can get priority inversion without explicit priority. We had such a problem caused by deep CPU throttling with CFS bandwidth control and it was causing application timeouts and down time.
To solve this problem we created a priority inheritance or priority ceiling like mechanism. The core idea of the solution is to treat the entire kernel mode as a critical section and not to throttle while in kernel mode. (There is an independently conceived, similar solution being discussed in lkml. We have posted the core part of our solution and they might merge - https://lore.kernel.org/all/xm26edfxpock.fsf@bsegall-linux.svl.corp.google.com)
Our solution not only reduced application timeouts, it also increased machine capacity. Each machine can now run a mix of workloads at higher CPU utilization without breaking down. We will discuss the solution, real-world data and data analysis.
The Energy Aware Scheduler has been developed with the assumption that tasks wake up regularly and often enough to keep their placement energy efficient and responsive. This assumption tend to be less and less true because of constraints like capping the performance of the system and the needs for still shorter response time. New mechanisms outside the wakeup path needs to be enabled to solve those issues. We will explore some possibilities to improve responsiveness while keeping energy aware decision and to move tasks stuck on an energy inefficient CPU.
In any system the overall system congestion behavior mainly revolve around CPU work-load, memory-pressure and IO-wait.
The Pressure Stall Information (PSI), introduced to monitor resource contention by tracking CPU, memory, and I/O pressure, provides real-time insights into system performance bottlenecks.
But the problem is, it just gives the overall average load value in the system during certain intervals.
For the end user it is still difficult to predict the workload share at task level.
This paper explores advancements in the PSI framework within the Linux kernel to enhance predictive workload analysis.
By extending the PSI framework with advanced predictive algorithms by monitoring resource usage at task level, we aim to accurately forecast workload patterns and resource demands.
This enhancement enables more efficient resource allocation, improved system responsiveness, and proactive performance tuning.
The proposed modifications to PSI are validated through extensive experimentation results, demonstrating significant improvements in workload prediction accuracy and overall system performance.
Power management features like DVFS introduces Time Dilation effect where progress of time slows down the lower the frequency from the task's perspective.
Combined with Heterogeneous systems (HMP) this Time Dilation become more extreme on the smaller cores. Especially on Arm mobile SoCs where the little cores are too small on many SoCs.
This manifests as big delays in task's rampup making the response time of the system mysterious from the observer's point of view. Usually manifests as complaints about 'latencies'.
There could be other potential side effects on fairness and wake up latencies while not focus of the talk, but items worth discussing to properly understand the impact on them, if any.
Assuming schedutil based systems. We want to explore:
At OSPM we had a number of discussions around the need for QoS APIs for applications to hint their needs for latency and throughput for SCHED_NORMAL/FAIR tasks, as opposed to the typical global tuning of scheduler knobs.
Folks seemed generally supportive of adding some sort of hinting API. However, while any hinting API will be coy and resistant to making any hard promises to userland about exactly what behavior may result from the hint, there seems to be a fair amount of fog around what we might actually do when an application hints that a certain thread would prefer lower latency response or more throughput.
Some potential actions we might take for low-latency hinting:
* When the task wakes up, allow it to preempt the currently running task
* Tweak its scheduler state so that the task’s placement in the runqueue will result in it being selected sooner
* Adjust cpu placement, so that when it wakes up, it’s more likely to be placed on idle cpus (though we must be careful not to pick ones in deep sleep states).
* Increase the cpu freq so running tasks can finish what they are doing allowing us to switch to our hinted task faster.
* [Other ideas?]
And for throughput focused tasks we might:
* Tweak the task's placement so it will be placed on bigger cpus
* Try to avoid other tasks preempting the hinted task, by placing woken tasks on other cpus
* Let the task run for longer slices
* More aggressively ramp up the cpufreq, by increasing the utilization estimation.
* [Other ideas?]
A big issue: the right thing to do in each case may very well depend on the hardware. So we may need some way to understand and abstract these choices. For instance: placement will need to be aware of the idle cpu wakeup latencies.
So once we've enumerated the possible actions, how do we configure which actions to take on which hardware?
We making good progress with zoned storage support in Linux, improving and adding support throughout the stack from low level drivers to file systems, user space tooling and cloud infrastructure. Since the last LPC MC on the topic, lots of stuff has happened, so it will be great to gather the community again, look back at what we've done, go through the issues we face today and discuss what we need to address next.
This is a brief summary of what has happened the last couple of years:
We propose that we spend half of the time allotted to summing up where we are today with quick overviews and then spend the second half with BOFs, kicking of discussions. It would be fun to finish up with post-mc beverages somewhere for continued discussions in an informal setting.
BoF ideas:
People that would be great to have in the room - usual suspects in this area along with people who have done research on the subject, in semi-random order:
Johannes Thumshirn(BTRFS)
Naohiro Aota(BTRFS)
Josef Bacik (BTRFS)
Bart Van Assche (Block layer, F2FS)
Daeho Jeong (F2FS)
Jaegeuk Kim (F2FS)
Boris Burkov (BTRFS)
Damien Le Moal (ZoneFS, block layer..)
Niklas Cassel (block layer)
Kuankuan Guo (User space file systems)
Pankaj Raghav (support non-power of 2 zoned devices)
Kanchan Joshi (block layer)
Keith Busch (NVMe)
Viacheslav Dubeyko(ssdfs)
Shai Bergman (swap research )
Abutalib Aghayev (research on ceph, ext4)
Luis Chamberlain (testing)
Javier Gonzales (research)
Andreas Hindborg (ublk)
Ming Lei (ublk)
Hans Holmberg(ZNS enablement, research, ZenFS, XFS)
Matias Bjorling (ZNS, research, ..)
Dennis Maisenbacher (cloud infrastructure, gc research)
Jorgen Hansen(research)
Hannes Reinecke
Christoph Hellwig
In this session we'll kick off the MC by summing up what has been going on in the Linux zoned storage space since the last LPC MC two years ago.
We'll focus on what is not covered by dedicated sessions later in the afternoon:
XFS is growing support for Zoned storage, and In this session we'll present and discuss the background, current state(including early benchmarks) and what's next for project, focusing on:
SSDFS natively supports ZNS SSD and is ready to employ FDP-based SSD. SSDFS provides multiple space saving techniques (compression, compaction, inflation model of erase block, deduplication, delta-encoding) that also work as techniques of decreasing write amplification. How do these techniques work together? How efficient could these techniques be for the case of ZNS SSD and FDP-based SSD? Which technique is better for which use-case? This talk is dedicated to discussing benefits and side effects of these techniques for the case of LFS file system and sharing benchmarking numbers (for example, the inflation model of the erase block is capable of storing up to 800 KB of user data into 128 KB erase block). How soon will SSDFS be stable and ready for production? Which performance number SSDFS can deliver?
Multiple Virtual Machines (VMs) workload is a widely deployed use-case. Let’s imagine a storage pool that can include multiple ZNS SSDs, SMR HDDs or a mixture of different types of storage devices (and, maybe, some computational power in the storage pool). The crucial question here is how to implement and deliver a flexible and efficient scheme of storage pool’s space distribution and management among the pool of VMs. It is possible to imagine a potential scheme that could employ a page table (virtual memory) likewise approach based on multiple user-space virtual block devices (ublk). Additionally, computational power in the storage pool can be used to guarantee reliability of stored data (by means of smart replication or erasure coding scheme, for example), to execute background live migration and load balancing of physical sectors with data (improving performance of operations). This talk is dedicated to discussion how can be implemented the efficient space management scheme of storage pool and which potential drawbacks could be hidden in the suggested approach.
This session is reserved for BOFs dedicated to continued discussions on topics presented earlier in the day (and other issues and ideas we should work on as a community). Contact the organizers if you have something you'd like to bring up.
Details will be listed on the back of you badge.
At Microsoft, we are working on a project called openHCL, which is a Linux-based paravisor featuring a user-mode virtualization stack.
For more details, you can check out this micro conference: LPC Event.
The paravisor is upgraded using a servicing operation where the old paravisor is shutdown and the new paravisor is booted into. Our goal is to minimize the
servicing time as much as possible. As part of this project, we manage several PCIe devices (e.g., NVMe) using VFIO (via vfio_pci_core.c). We have identified
that tearing down and reinitializing the devices takes a significant portion of this servicing time. To avoid this extra latency, we are considering making the DMA
buffers persistent across reboots and avoiding any actions (hardware access) that could alter these buffers. Since we are using noiommu option, the saving and
restoring IO pages is not a concern, also hypervisor allows to keep the physical pages intact which allowed us to keep the DMA buffers persistent across boots.
This solves the first part of the problem.
The another part of the solution is to keep the NVMe device alive across reboots with its hardware configurations intact. We have observed that accessing PCI
device registers in vfio_pci_core.c can trigger DMA actions, which may alter the DMA buffers. For example, the pci_clear_master function clears the
"Bus Master" bit, which resets the controller and invalidates all DMA buffers.
To prevent hardware access through VFIO following a reboot, we are considering implementing a flag to avoid all these hardware access. This flag can be passed
through a new vfio ioctl or sysfs, but we are also open to alternative methods that could be more appropriate for integrating this solution into the upstream.
A topic rife with misinformation and emotional reactions, it's time to give another opportunity for folks to ask questions about and discuss GPL and LGPL enforcement together. The last BoF at Plumbers, in 2016 had lively discussion and great input that informed Software Freedom Conservancy's efforts in the following years. At that BoF, and privately since then, Software Freedom Conservancy has received almost entirely encouraging and supportive feedback from developers. At the same time, we know some companies discourage any active efforts to mandate compliance. The only way to understand what people think and to address misinformation bouncing around the community is to actually discuss it in a place where anyone who is interested can participate. Let's share information and hear what everyone thinks! If the organizers allow, this BoF won't be recorded and we'll ask attendees not to relay who said what without permission.
PCIe 6.0 introduced device authentication and encryption (sec 6.31 and 6.33). We are bringing up kernel support, seeking consensus with the community at past Plumbers installments (2023, 2022, 2021).
We would like to continue this fine tradition by presenting our progress since last year's Plumbers and having an open discussion on the next steps towards mainline.
An updated patch set for PCI device authentication was submitted in June 2024. It addresses three key requests raised at last year's Plumbers:
Transparency log:
The kernel exposes a log of signatures received from the device in sysfs, which allows for their re-verification by remote attestation services. Requested by James Bottomley.
Code reuse and common ABI with ATA and SCSI:
ATA and SCSI are adopting the generic SPDM protocol upon which PCI device authentication is built. The kernel implementation has been amended to allow for code reuse by ATA and SCSI subsystems and a common user space ABI. Requested by Damien Le Moal.
Coexistence with TSMs:
Recent CPUs are integrating Trusted Security Modules (TSMs) which set up PCI device authentication and encryption for confidential DMA from a device into encrypted guest memory. Dan Williams is working on a patch set to negotiate between kernel and TSM which of the two is responsible for PCI device authentication and encryption.
We are particularly keen to hear feedback on the user space ABI for certificate and signature exposure and on remaining blockers seen by community members.
We would also like to discuss upcoming features such as certificate provisioning, measurement retrieval and encryption setup.
The audience of this BoF includes PCI, CXL and confidential computing developers.
This BoF will be an opportunity to discuss Linux kernel debugging tools, with a primary focus on Drgn. Discussion will be attendee-driven, some example discussion topics could be:
However any kernel debugging discussion would be welcome and encouraged!
The COCONUT-SVSM community wants to get in contact with the wider Linux and virtualisation community and gather ideas, discuss problems and get input for the next year of development.
Therefore we invite everyone interested in Confidential Computing and the SVSM to join us in this BoF.
There are several efforts to support memory persistence over kexec:
PKRAM [1]: Tmpfs-style filesystem which dynamically allocates memory which can be used for guest RAM and is preserved across kexec by passing a pointer to the root page.
Kexec Hand Over (KHO) [2]: This is a generic mechanism to pass kernel state across kexec. It also supports specifying persisted memory page which could be used to carve out IOMMU pgtable pages from the new
+kernel's buddy allocator.
Kernel memory pools [3, 4]: These provide a mechanism for kernel modules/drivers to allocate persistent memory, and restore that memory after kexec. They do do not attempt to provide the ability to store
+userspace accessible state or have a filesystem interface
Pkernfs [5] that attempted to solve guest memory persistence and IOMMU persistence all in one and guestmemfs [6] that is a re-work of that to only persist guest RAM in the filesystem, and to use KHO for
+filesystem metadata.
All these proposals address slightly different use-cases and it's highly desirable to decide how the solution that will work for all these use-cases should look.
Gathering all interested parties in one room and not letting them out for beers before they reach a consensus seems an obvious route to take in this situation.
[1] https://lore.kernel.org/kexec/1682554137-13938-1-git-send-email-anthony.yznaga@oracle.com/
[2] https://lore.kernel.org/kexec/20231213000452.88295-1-graf@amazon.com/
[3] https://lore.kernel.org/all/169645773092.11424.7258549771090599226.stgit@skinsburskii./
[4] https://lore.kernel.org/all/20231016233215.13090-1-madvenka@linux.microsoft.com
[5] https://lore.kernel.org/all/20240205120203.60312-1-jgowans@amazon.com/
[6] https://lore.kernel.org/linux-mm/20240805093245.889357-1-jgowans@amazon.com/
Compute Express Link is a cache coherent fabric that has been gaining momentum in the industry. Whilst the ecosystem is still catching up with CXL 3.0 and earlier features, CXL 3.1 launched just after the 2023 CXL uconf, bringing yet more challenges for the community (temporal sharing, advanced RAS features). There also has been controversy and confusion in the Linux kernel community about the state and future of CXL, regarding its usage and integration into, for example, the core memory management subsystem. Many concerns have been put to rest through proper clarification and setting of expectations.
The Compute Express Link microconference focuses on how to evolve the Linux CXL kernel driver and userspace components for support of the CXL specifications. The microconference provides a place to open the discussion, incorporate more perspectives, and grow the CXL community with a goal that the CXL Linux plumbing serves the needs of the CXL ecosystem while balancing the needs of the Linux project. Specifically, this microconference welcomes submissions detailing industry and academia use cases in order to develop usage model scenarios. Finally, it will be a good opportunity to have existing upstream CXL developers available in a forum to discuss current CXL support and to communicate areas that need additional involvement.
The earlier editions of the microconference resolved a number of open questions (CXL 1.1 RAS now upstream), and introduced new topics we expect to revisit this year (e.g. dynamic capacity / shared memory and error handling)
Suggested topics:
Ecosystem & Architectural review
Dynamic Capacity Devices - Status and next steps
Inter host shared capacity
Fabric Management - What should Linux enable (blast radius concerns)? Open source solutions?
Error handling and RAS (including OCP RAS API)
Testing and emulation
Security (ie: IDE/SPDM)
Managing vendor specificity
Virtualization of dynamic capacity.
Type 2 accelerator support - CXL 3.0+ approaches.
Coherence management of type2/3 memory (back-invalidation)
Peer2Peer (ie: Unordered IO)
Reliability, availability and serviceability (ie: Advanced Error Reporting, Isolation, Maintenance).
Hotplug (QoS throttling, policies, daxctl)
Hot remove
Documentation
Memory tiering topics that can relate to cxl (out of scope of MM/performance MCs)
Industry and academia use cases
A brief hello from the CXL uconf organizers.
The usual collection of small administrative elements.
CXL introduced Dynamic capacity device support in CXL 3.0 and 3.1. The feature
promises a lightweight memory hotplug feature which was designed to optimize
memory usage within data centers. The details of use cases for DCDs are still
playing out. Generally the use case is to reduce the cost of unused memory by
allowing for the dynamic allocation of memory.
Compute Express Link (CXL) is a low-latency, high-bandwidth, heterogeneous, and cache-coherent interconnect between a CPU or a device and other accelerator or memory devices. With CXL Type 3 Devices the memory is located on a device but can be used as system memory, the same as standard memory. This allows a flexible way to assign and manage system memory using memory devices.
As various components and different protocols and subsystems are involved in memory access, the handling of CXL errors becomes challenging. CXL provides RAS features to report and handle errors.
Error handling support has been added to recent kernels and development is still ongoing. This talk gives an update and a development outlook on CXL error handling.
Beyond simple error reporting, the CXL specification defines many features related to RAS. Examples being Memory Patrol Scrub and ECS control + features such as PPR directed at the runtime repair of memory. Whilst part of our motivation for looking at this area was to support the CXL features, moves such as OCP RAS API suggest there will be future opportunity for reuse.
There is considerable overlap with existing features distributed across the kernel so when we came to implement Scrub Control we proposed a new subsystem to unify the control interfaces, starting with driver support for the CXL feature and equivalent ACPI RAS2 feature. That proposal was intentionally separate from existing infrastructure to avoid legacy challenges and reflecting the fact that RAS in general has become highly distributed across kernel subsystems with the unification point being tools such as RASDaemon (user space). Perhaps this suffered from the 'lets make a new standard' to unify all these existing standards problem.
https://lore.kernel.org/all/20240419164720.1765-1-shiju.jose@huawei.com/
Feedback on that proposal included the question of why EDAC was not suitable, with one valid concern being that a separate overlapping subsystem would divide the review community and reduce quality for everyone.
EDAC is a very mature subsystem carrying a lot of legacy support that makes little sense if we are supporting new features (and hence avoid concerns about ABI breakage). The latest proposal is to use it as a 'home' bringing the benefits of a unified location in /sys/bus/edac and ensuring those most familiar with RAS features are heavily involved in the design, but use a modern subsystem design with simpler user of the kernel device model.
This session will include:
* Motivations for exposing the features at all.
* A brief summary of the proposed design (it's simple so won't take long!)
* An outline of future roadmap (if time)
Inputs sought on:
- Relevance of use cases - which ones matter as we need motivating example / user space code.
- Does unification actually make sense?
As the author of a current RFC patchset under review for supporting a Type2 CXL device, it is worth to summarize what has been discussed so far, the current status of the patchset and also other tangential concerns like full privacy or CXL/PCIe slot resets and restoring CXL registers.
CXL.cache needs also to be discussed with the goal of defining a roadmap or at least first steps towards fully support, likely starting with security for restricting what a CXL.cache capable device can do. I will present a template for trying to define those goals.
CXL version 3 supports shared memory that must remain separate from
system-RAM. This talk will cover the following:
This a logical followup to my LPC talk last year [2] and my LSFMM talk
on famfs earlier this year [3].
[1] https://github.com/cxl-micron-reskit/famfs/blob/master/README.md
[2] https://lpc.events/event/17/contributions/1455/
[3] https://www.youtube.com/watch?v=nMaZhXJJgmU&list=PLbzoR-pLrL6oj1rVTXLnV7cOuetvjKn9q&index=66
This talk will present 'libcxlmi', a CXL Management Interface utility library. It provides type definitions for CXL specification structures, enumerations and helper functions to construct, send and decode CCI commands and payloads over both in-band (Linux) and out-of-band (OoB) link, typically MCTP-based CCIs over I2C or VDM.
The objective of this presentation is both to cover the design and implementation of the library, as well as opening the floor for discussion about how people want to make best use of it as well as general requirements.
The intended audience are developers (OEMs) interested in building CXL based solutions, such as BMCs and firmware, to communicate with various components.
Benchmarking and efficiency estimation of CXL infrastructure is a crucial task for the whole CXL ecosystem. Which tool(s) can be used and how can we execute such benchmarking? Potentially, a benchmarking tool could simulate the target use-case (for example, huge relational database, in-memory database, huge social network, ML model training, Virtual Machine use-case, HPC use-case, and so on). But, technically speaking, we need a tool that is capable of generating workloads with the opportunity of tuning various parameters (allocation/deallocation size, total allocation size, allocation/deallocation pattern, read/write pattern, memory type selection policy, migration policy, threads number and so on). I would like to suggest the discussion which tuning parameters are really crucial and how we can implement and deliver the CXL benchmarking infrastructure.
CFP closes on July 12th.
KVM (Kernel-based Virtual Machine) enables the use of hardware features to
improve the efficiency, performance, and security of virtual machines (VMs)
created and managed by userspace. KVM was originally developed to accelerate
VMs running a traditional kernel and operating system, in a world where the
host kernel and userspace are part of the VM's trusted computing base (TCB).
KVM has long since expanded to cover a wide (and growing) array of use cases,
e.g. sandboxing untrusted workloads, deprivileging third party code, reducing
the TCB of security sensitive workloads, etc. The expectations placed on KVM
have also matured accordingly, e.g. functionality that once was "good enough"
no longer meets the needs and demands of KVM users.
The KVM Microconference will focus on how to evolve KVM and adjacent subsystems
in order to satisfy new and upcoming requirements. Of particular interest is
extending and enhancing guest_memfd, a guest-first memory API that was heavily
discussed at the 2023 KVM Microconference, and merged in v6.8.
The KVM MC is expected to have strong representation from maintainers (KVM and
non-KVM), hardware vendors (Intel, AMD, ARM, RISC-V, etc), cloud (AWS, Google,
Oracle, etc), client (Android, ChromeOS), and open source stalwarts such as
Red Hat and SUSE.
Potential Topics:
- Removing guest memory from the host kernel's direct map[1]
- Mapping guest_memfd into host userspace[2]
- Hugepage support for guest_memfd[3]
- Eliminating "struct page" for guest_memfd
- Passthrough/mediated PMU virtualization[4]
- Pagetable-based Virtual Machine (PVM)[5]
- Optimizing/hardening KVM usage of GUP[6][7]
- Live migration support for guest_memfd
- Defining KVM requirements for hardware vendors
- Utilizing "fault" injection to increase test coverage of edge cases
[1] https://lore.kernel.org/all/cc1bb8e9bc3e1ab637700a4d3defeec95b55060a.camel@amazon.com
[2] https://lore.kernel.org/all/20240222161047.402609-1-tabba@google.com
[3] https://lore.kernel.org/all/CABgObfa=DH7FySBviF63OS9sVog_wt-AqYgtUAGKqnY5Bizivw@mail.gmail.com
[4] https://lore.kernel.org/all/20240126085444.324918-1-xiong.y.zhang@linux.intel.com
[5] https://lore.kernel.org/all/20240226143630.33643-1-jiangshanlai@gmail.com
[6] https://lore.kernel.org/all/CABgObfZCay5-zaZd9mCYGMeS106L055CxsdOWWvRTUk2TPYycg@mail.gmail.com
[7] https://lore.kernel.org/all/20240320005024.3216282-1-seanjc@google.com
Nowadays, there are various needs to run a VM in the public cloud, such as running a security container to isolate workloads or encapsulating an application into a VM for migration or rapid kernel testing utilizing cost-effective spot VMs. However, nested virtualization on KVM requires hardware support and is usually disabled by the cloud provider for safety reasons. Additionally, the current nested architecture involves complex and expensive transitions between the L0 hypervisor and L1 hypervisor. Therefore, we are introducing a new virtualization framework built upon the KVM hypervisor that does not require hardware-assisted virtualization techniques. This framework serves as a PV flavor for KVM, allowing the running of a VM in the public cloud without nested virtualization support.
We have provided our RFC patch set to present the PVM design. In this session, we plan to share various use cases of PVM and present its inherent value. In particular, we want to discuss the underlying technology associated with the x86 subsystem and the KVM subsystem, and the aspects of these subsystems improved in the implementation of PVM (e.g. improved shadow paging which also helps for nested TDP), as well as the collaboration to consolidate the work for the future. Moreover, we would also like to address the security model (e.g. side channel attacks between guest/host) in PVM compared to other PV virtualization implementations. Furthermore, we aim to explore the possibility of extending PVM to more architectures (e.g. ARM64 and RISC-V) to establish it as a common PV flavor for KVM.
KVM has supported vPMU for years as the emulated vPMU. In particular, KVM presents a virtual PMU to guests where accesses to PMU get trapped and converted into perf events. These perf events get scheduled along with other perf events at the host level, sharing the HW resource. In the emulated vPMU design, KVM is a client of the perf subsystem and has no control of the HW PMU resource at host level.
This emulated vPMU has these drawbacks:
Poor performance. Existing emulated vPMU has a terrible performance [1]. When guest PMU is multiplexing its counters, the situation is even worse, ie., KVM wastes the majority of time re-creating/starting/releasing KVM perf events, leading to significant performance degradation.
Silent error. Guest perf events's backend may be swapped out or disabled silently. This is because the host perf scheduler treats KVM perf events and other host perf events equally, they will contend HW resources. KVM perf events will be inactive when all HW resources have been owned by host perf events. But KVM can not notify this backend error into guests, this silent error is a red flag for vPMU as a production.
Hard to add new vPMU features. For each vPMU new feature, KVM may need to emulate new PMU MSRs, this involves changes to the perf API. Vendor specific changes that complicate the perf API are hard to be accepted. In addition, the whole design becomes complicated because of the "sharing" requirement, and makes the above "silent error" even worse. Because of these reasons, features like PEBS, vIBS, topdown are hard to be added.
In the new vPMU implementation, we pass through all PMU MSRs instructions except for event selectors (for security reasons), ie., all PMU MSR accesses directly touch the PMU HW instead of going to perf subsystem on the host. This means when guest is running, guest PMU is excluding owning the whole PMU hardware until it context switches back to the host.
For PMU Context switches, we do full context save/restore on the VM Enter/Exit boundary, in which we save the guest PMU MSR values that we pass through and restore the corresponding values for the host.
For PMI handling, our design leverages a dedicated interrupt vector for the guest PMI, i.e., When a guest is running and using PMU, PMIs for the guest are then delivered to the PMI handler (causing a VMEXIT) and then KVM injects the PMI into the guest.
With mediated passthrough vPMU design, VM can enjoy the transparency of x86 PMU HW. Our latest version integrates AMD support for mediated passthrough, making it complete for the whole x86 architecture.
Overall this new design has the following benefits:
Better performance. when guest access x86 counter PMU MSRs, no VM-exit and no host perf API call.
Exclusive ownership on PMU HW resources. Host perf events are stopped and give up HW resource at VM-entry, and restart running after VM-exit.
Easy to enable PMU new features. KVM just needs to pass through new MSRs and save/restore them at VM-exit and VM-entry, no need to add perf API.
Note, passthrough vPMU does satisfy the enterprise-level requirement of secure usage for PMU by intercepting guest access to all event selectors. In addition, the new vPMU design checks the exposure of PMU counter MSRs and decides whether to intercept RDPMC or not. We pass through RDPMC if and only if all PMU counters are exposed.
The key problem of mediated passthrough vPMU is that the host user loses the capability to profile guests. If any users want to profile guests from the host, they should not enable the new vPMU mode. In particular, perf events with attr.exclude_guest = 1 will be stopped here and restarted after vm-exit. In RFCv1, these events without attr.exclude_guest=1 will be in error state, and they cannot recover back to active state even if the guest stops running. This impacts host perf a lot and requests host system wide perf events have attr.exclude_guest=1. In RFCv2, we update the design by making sure the VM can't be started when !exclude_guest events exist on host and host !exclude_guest events are blocked to create when VM has been started. In addition, exclude_guest attribute would be set by default when perf tool creates events.
Other than the above, there are several open topics under intensive discussion:
NMI watchdog. the perf event for NMI watchdog is a system wide cpu pinned event, it will be stopped also during vm running, but it doesn't have attr.exclude_guest=1, we add it in this RFC. But this still means the NMI watchdog loses function during VM running. Two candidates exist for replacing perf event of NMI watchdog:
Buddy hardlock detector[3] may be not reliable to replace perf events.
HPET-based hardlock detector [4] isn't in the upstream kernel.
Dedicated kvm_pmi_vector. In emulated vPMU, host PMI handlers notify KVM to inject a virtual PMI into the guest when the physical PMI belongs to the guest counter. If the same mechanism is used in passthrough vPMU and PMI skid exists which causes physical PMI belonging to guests to happen after VM-exit, then the host PMI handler couldn't identify this PMI belongs to host or guest. So this RFC uses a dedicated kvm_pmi_vector, PMI belonging to guests has this vector only. The PMI belonging to the host still has an NMI vector.
The location of the PMU context switch. There is an intensive discussion on the location of the PMU context switch. Existing implementation does the context switch at VM-enter/exit boundary. This generates a moderate performance overhead per VMEXIT due to PMU register reads and writes. One alternative idea is to put the PMU context switch location to the VCPU_RUN loop boundary. However, the downside of that is the missing functionality of profiling KVM code within the VCPU_RUN loop. The debate is still ongoing.
[1] Efficient Performance Monitoring in the Cloud with Virtual Performance Monitoring Units (PMUs) https://static.sched.com/hosted_files/kvmforum2019/9e/Efficient%20Performance%20Monitoring%20in%20the%20Cloud%20with%20Virtual%20PMUs%20%28KVM%20Forum%202019%29.pdf
[2] Mediated Passthrough vPMU v1 https://lore.kernel.org/all/20240126085444.324918-1-xiong.y.zhang@linux.intel.com/
[3] Mediated Passthrough vPMU v2 https://lore.kernel.org/all/20240506053020.3911940-1-mizhang@google.com/
This session should group discussions on future extensions to guest_memfd, including:
This talk presents different proposals for supporting guest private memory in Android for Arm64 in the pKVM and the Gunyah hypervisors.
Confidential computing is gaining popularity, with hardware-based (Intel TDX, AMD SEV, Arm CCA) and software-based (pKVM, Gunyah) solutions. A common aspect is the ability to create a "protected" guest, whose data is neither inaccessible by other VMs nor by the host itself, unless explicitly shared by the guest.
In the original KVM API, guest memory is provided as a host user space address to KVM, and is mapped by the host. Although the hypervisor prevents the host from accessing the guest memory via that address, an erroneous access could be fatal to the system and result in a full reset.
To address these issues, guest_memfd() was created as a new API. It represents guest memory using a file descriptor, along with an allocator that restricts what can be done with that memory, such as mapping it at the host. With the guest memory not being mappable to begin with, erroneous accesses cannot take place.
The pKVM and the Gunyah hypervisors target mainly Android on Arm64. They use hypervisor (stage 2) page table protection, not encryption, to protect guest memory. Among other things, this allows in-place guest memory conversion between shared and private. However, the current guest_memfd() implementation never allows guest memory mapping, and sharing is done by copying the data
In this talk, we propose modifications to guest_memfd(), as well as alternative approaches, to enable these hypervisors to perform shared to private conversions in-place (and vice versa).
So far, we have presented two proposals as RFCs upstream [1, 2], followed by discussions on the best approach moving forward. This talk aims to summarize these discussions to reach a solution consistent with existing approaches.
[1] https://lore.kernel.org/all/20240222161047.402609-1-tabba@google.com/
[2] https://lore.kernel.org/all/20240618-exclusive-gup-v1-0-30472a19c5d1@quicinc.com/
guest_memfd is a new feature providing a guest-first memory subsystem internal to KVM. Being internal to KVM opens guest_memfd up to virtualization-specific features, enhancements and optimizations.
A notable feature that guest_memfd currently lacks is 1G page support.
Here are some key benefits of 1G page support:
Better performance due to
Increased hit rate in the TLB
Faster page table walks in case of TLB misses
Memory savings due to smaller page table
Further memory savings due to Vmemmap optimization
Support for 1G pages is crucial to support large virtual machines, which are becoming more common due to growing usage of GPU and other AI accelerator hardware such as TPUs.
Specifically for Confidential Virtual Machines (CVMs), there are further challenges in using 1G pages as guests tend to require conversion of memory ranges between two memory classes, private and shared, at granularities smaller than 1G.
We previously explored providing 1G pages from the hugetlb subsystem because the hugetlb subsystem already provides useful features such as a pool of huge pages to the kernel at boot time, together with page accounting, memory charging and reporting.
In this presentation, we want to
Present some known requirements (and hope to gather more) of 1G page support in guest_memfd, potentially including
Sharing of 1G page pool with other subsystems
Setting up pages for host CPU/IO access to guest_memfd
Explore and compare options for adding 1G page support including using the hugetlb subsystem
Explain challenges of using guest_memfd in CVMs and possible solutions
Discuss the best way of landing this support in the kernel
Since the discovery of Spectre and Meltdown in 2018, transient execution attacks are being discovered regularly, both in old and new hardware. Mitigation involves applying specific patches for each vulnerability, and is often costly in terms of performance, leading to cloud computing providers to seek more general mitigations.
The majority of these attacks are based on the presence of a machine's entire physical memory in host kernel address space. Carefully crafted malicious software may influence CPU execution by mistraining branch predictor units so that the CPU speculatively accesses data in the kernel context and leaves non-architectural side effects of that activity, such as loading certain data in the CPU cache, which can be observed by the attacker to infer sensitive content.
We propose mitigating these attacks by removing page table mappings of sensitive memory regions from kernel address space, thus preventing malicious speculative loads and their side effects altogether. This makes memory immune to a large class of both known and not-yet-discovered transient execution attacks. We will discuss KVM patch series for securing the entirety of a virtual machine's memory against these types of issues, by extending KVM's guest_memfd to remove its memory from the kernel's direct map. guest_memfd is a fd-based backend for guest memory (as opposed to the traditional VMA-based backend) introduced in Linux 6.8, inspired by confidential compute technologies such as Intel TDX and AMD SEV-SNP, which we are interested in extending to the non-CoCo usecase.
The key challenge with post-copy live migration is intercepting accesses to particular pages of guest memory. Today, the only way to do this is to use userfaultfd, an mm feature that intercepts page faults (and other events). KVM, after translating a GFN to an HVA, will call GUP to translate the HVA to an HPA, thereby triggering userfaultfd.
When using guest_memfd, KVM does not use GUP to translate from GFN to HPA, nor is there a GFN-to-HVA translation step. Therein lies the problem: userfaultfd cannot intercept these translations, making post-copy live migration impossible.
Given that guest_memfd is entirely separate from the main mm fault handling logic, either (1) userfaultfd must be extended to handle non-mm faults, or (2) something else needs to be created.
There are at least two options for how userfaultfd could potentially be extended: (1) add KVM-related operations to it, or (2) add file-related operations to it (for guest_memfd). Both are complex.
We can limit the overall added complexity by adding a KVM-based post-copy solution. Let’s call it KVM Userfault. At its core, we need:
The most straightforward way to inform KVM of which pages should fault and which should not is to use a new memory attribute. Doing so has several challenges, especially with respect to performance/scalability. Another possibility is to use a separate, potentially bitmap-based UAPI.
With respect to notifying userspace of faults, for vCPU faults, we can use KVM_EXIT_MEMORY_FAULT. For other faults (e.g. when KVM itself is accessing guest memory), we likely need to use a userfaultfd-like asynchronous notification. Although KVM does not itself read guest_memfd memory today, after guest_memfd supports shared memory, this will become a possibility.
The KVM-based solution is crudely implemented in the KVM Userfault RFC, using memory attributes and including asynchronous userfaults.
The focus of this microconference will be on topics related to the APIs and interfaces sitting at the boundary between the kernel and init systems/system management layers, with a special attention directed towards current pain points and omissions.
For example, issues around the current way initrd are loaded and set up between the bootloader and the kernel as we move towards immutable systems, or the interfaces provided by the kernel around the mount or cgroup or pidfd APIs as consumed by systemd or other service managers, or the uevent interactions between the kernel and udev.
We expect submissions to be either open discussions or presentations that discuss new proposals/ideas, ongoing work, or problems we are/should be solving in this space. Submissions are recommended to be 15 - 45 minutes long. Please specify the format, the desired length of your submission, and how much, if any, additional time to allocate for discussion in your abstracts.
The current way most Linux systems use initrds is via the initramfs mechanism: a compressed cpio archive is generated via an initrd generator and passed to the kernel at boot. The kernel then decompresses this cpio archive at boot into a fresh tmpfs file system. This file system is then booted.
This is not ideal for various reasons: the tmpfs can never be unmounted, hence must be emptied when transitioning into the host. Morever, the a lot of work needs to be done ahead of time, touch the whole data in the initrd, even if not all files will be needed on a specific system. The fact that the tmpfs is writable is not ideal either.
Let's hence investigate how we can improve the situation, to make boots quicker, safer and the initrd image process reproducible and attestable.
This session is more about discussing various options and challenges, there's no ready-made proposal behind this session.
Ideas: mounting erofs from memory instead of cpio, making initial superblock unmountable, using pmem= on the kernel command line, and more.
Secure systems need to control code execution, to either deny untrusted (and potentially malicious) code, or to run it in a confined environment (i.e. a sandbox restricting access to resources). Linux provides a wide range of access control systems for different use cases but one remaining major gap is script execution control. Indeed, the kernel can only mediate access to resources it manages, but scripts are executed by interpreters that are not aware of the system security policy. In a nutshell: ./script.sh vs. sh script.sh
We are proposing to close this gap with a set of new kernel features (previously known as O_MAYEXEC). This is the first step to be able to have full control over code executed on a system. The next steps include script interpreters and dynamic linkers enlightenment, but also configuration of the execution policy by system components.
We'll first give an update on the ongoing kernel side implementation, and we'll explain the reasons leading to these interfaces, including perquisites and limitations.
We'd then like to discuss and answer questions about code execution control, the current status in user space changes (e.g. Python), and especially the required changes to system components in charge of launching services and applications to control the execution policy (e.g. with systemd's unit).
Systemd does various checks and extensive preparation of the environment in which it'll spawn an executable. Currently, this is subject to a TOCTOU race, because we access the binary by path. We have code ready to use an fd for everything, but unfortunately the process that is spawned has a bogus COMM value (the fd number), which breaks ps -C …. To make fexecve / execveat fully usable for userspace, we need to have a way to override /proc/self/comm for the executed process.
In the talk, I'll provide a short motivation why this feature is useful, what the current shortcomings are, and open the discussion to hopefully come up with an (simple) addition to the kernel API to fill in this missing bit.
Process ID File Descriptors were introduced in Linux v5.3. They allow tracking a process reliably, without risking races and reuse attacks, as they always refer to one single process regardless of the actual PID, so if the process goes away the file descriptor will become invalid, even if a new process with the same PID reappears at the same time.
Recently work has been done to plumb PID FDs through low-level userspace components - glibc returns the child's PID FD on pidfd_spawn(), systemd tracks processes via PID FDs and is able to receive queries asking for the session information or unit information via a PID FD, D-Bus implementations return the PID FD of a D-Bus endpoint via GetConnectionCredentials()/GetConnectionUnixProcessFD() (and they track processes via FD rather than PID), and Polkit allows writing rules authorizing by the systemd service name, which is possible to do safely thanks to using FDs all the way through. And now there is a new in-kernel pseudo-filesystem that assigns a unique ID to each PID FD, that never wraps.
We'll quickly summarize what we have and what use cases PID FDs have made possible, and then we'll move on to talk about what the next steps should ideally be in order to further enhance the feature and provide more functionality for userspace.
The UAPI Group has been maintaining a kernel API wishlist for a while, listing various API ideas for the Linux kernel, that address needs and wishes from various low-level developers. In this session, let's talk about currently listed items, and the what and why behind them.
https://uapi-group.org/kernel-features/
Read-copy update (RCU) ensures that any update carried out prior to the
beginning of an RCU grace period will be observed by the entirety of any
RCU reader that extends beyond the end of that grace period. Waiting for
grace periods is the purpose of the synchronize_rcu() function, which
waits for all pre-existing readers in a throughput-optimized manner
with minimal impact on real-time scheduling and interrupt latencies,
but which might well wait for many tens of milliseconds.
This synchronize_rcu() function is a key component of per-CPU
reader-writer semaphores, where it enables writers to wait until all
readers have switched to the writer-aware slow path. In the scheduler's
CPU-deactivate code, synchronize_rcu() waits for all readers to become
aware of the inactive state of the outgoing CPU. A few other examples
uses include module unload, filesystem unmount, and BPF program updates.
Therefore, improving synchronize_rcu() latency should improve the latency
of a great many Linux-kernel components.
This talk will present an analysis of synchronize_rcu() latency that
identified issues during RCU callback floods, that is, high call_rcu()
invocation rates. These issues motivate a new approach that decouples
processing of synchronize_rcu() wakeups from the processing of RCU
callbacks. This approach provides from 3-22% improvements in launch
latency for an Android camera application when running on devices that
do not boot with synchronize_rcu() mapped to synchronize_rcu_expedited(),
a choice that might help avoid jitter in real-time applications.
However, there are currently a few downsides of this low-wait-latency
synchronize_rcu() implementation: (1) The global wait list will result
in excessive contention on systems with many CPUs; (2) Wakeups depend
on kworker execution which might degrade wait latency; (3) Wakeups are
carried out in LIFO order, and (4) Potential issues that might arise
from high synchronize_rcu() invocation rates, for which RCU's existing
callback handling has been heavily optimized. Due to these downsides,
the current implementation is enabled only on systems such as embedded
devices having low CPU counts. Future work will address these downsides
in the hope that low-wait-latency synchronize_rcu() can be deployed by
default on all systems.
Outline the major pain points why Linux kernel regressions happen and why resolving some takes a long time as observed by Thorsten during three years of working as the kernel's regression tracker.
The talk among others will describe why some workflow patterns are what frequently leads to regressions -- and why they are also a factor why some subsystems fix regression quickly, while others take weeks or months to resolve.
While at it, describe what testers, bug reporters, developers, and maintainers can do to prevent regressions and resolve them more quickly. Furthermore also cover regzbot, the Regression Tracking Bot Thorsten uses for his work: what it learned in the recent past, what's on its roadmap, and where it works poorly or well in practise.
While doing all of the above, keep the audience involved and foster discussion about the discussed points and anything related.
Assuming Thorsten is invited to the Linux maintainers summit happening right before the LPC, he'll start this session by quickly recapping what has been discussed and decided regarding bug/regression reporting, tracking and handling there.
Rust for Linux is the project adding support for the Rust language to the Linux kernel. This talk will give a high-level overview of the status and the latest news around Rust in the kernel since LPC 2023.
Open-source software is increasingly reused, complicating the process of patching to repair bugs. In the case of Linux, a distinct ecosystem has formed, with Linux mainline serving as the upstream, stable or long-term-support (LTS) systems forked from mainline, and Linux distributions, such as Ubuntu and Android, as downstreams forked from stable or LTS systems for end-user use. Ideally, when a patch is committed in the Linux upstream, it should not introduce new bugs and be ported to all the applicable downstream branches in a timely fashion. However, several concerns have been expressed in prior work about the responsiveness of patch porting in this Linux ecosystem. In this paper, we mine the software repositories to investigate a range of Linux distributions in combination with Linux stable and LTS, and find diverse patch porting strategies and competence levels that help explain the phenomenon. Furthermore, we show concretely using three metrics, i.e., patch delay, patch rate, and bug inheritance ratio, that different porting strategies have different tradeoffs. We find that hinting tags(e.g., Cc stable tags and fixes tags) are significantly important to the prompt patch porting, but it is noteworthy that a substantial portion of patches remain devoid of these indicative tags. Finally, we offer recommendations based on our analysis of the general patch flow, e.g., interactions among various stakeholders in the ecosystem and automatic generation of hinting tags, as well as tailored suggestions for specific porting strategies.
Power fluctuations are a common challenge in embedded systems, where components like SD cards, eMMCs, and raw NAND flash are widely used for storage. These storage components are vulnerable to data corruption or even permanent damage when power unexpectedly drops. While larger systems, such as servers, often employ solutions like uninterruptible power supplies (UPS) to mitigate this risk, the size and cost constraints of embedded devices often preclude such measures. Although some modern embedded systems can detect power issues early, a unified, upstream solution for gracefully shutting down critical components is still lacking.
In fact, software-based solutions for prioritized shutdown already exist in some Linux-based embedded systems. However, these solutions are not integrated into the mainline kernel. This fragmentation makes it difficult for the broader community to benefit from these advancements.
This talk aims to bridge this gap by advocating for the inclusion of prioritized shutdown mechanisms in the Linux kernel. We will discuss the unique challenges faced by embedded systems, where size and cost constraints often limit hardware-based protections like UPS systems. By leveraging existing software solutions and collaborating with the community, we can develop a standardized approach to power loss protection that benefits all embedded Linux users.
Join us as we explore the technical and community aspects of this issue, with the goal of making graceful shutdowns a standard feature in all Linux-based embedded systems. Let's work together to protect our data, even when the power flickers.
In the context of starting the Nova driver project [1] it was decided to upstream Nova bit by bit and start with only a "stub" driver, in order to break the chicken-egg problem of Rust drivers requiring C API abstractions while upstreaming C API abstractions require at least one user.
As the one driving this project and this first effort, this talk is about sharing my experience from the following perspectives.
How did it go to start a new project in Rust in the kernel as a long time C kernel engineer without much prior knowledge of the Rust programming language, while also having the need to upstream major parts of the required abstractions for the project?
What were the difficulties and pitfalls in upstreaming the required abstractions and which are the typical challenges in having people with different backgrounds involved?
[1] Rust DRM driver for Nvidia GSP-based GPUs; separate talk in the main track ("Nova - a Rust DRM driver for NVIDIA GPUs")
There is a class of physical devices that contain several discrete modules in a single package but which are represented in the kernel as separate entities. An example of such devices is the Qualcomm WCN/QCA family of WLAN/Bluetooth adapter chipsets.
Typically the WLAN and Bluetooth modules will have their own device-tree nodes - one under the PCI bridge (WLAN) and one under the serial node (Bluetooth). The relevant drivers will bind to these devices and consume assigned resources (which are usually already reference counted).
The problem arises when the two modules packaged together have interdependencies - for instance: a chipset may require a certain delay between powering-up the Bluetooth and WLAN modules (an example: Qualcomm QCA6490). In this case, reference counting alone is not sufficient and we need more fine-grained serialization.
In order to support such devices, a new driver subsystem has been proposed: the power sequencing framework[1]. It allows to abstract the shared powering-up/-down operations for multiple devices into a separate power sequence provider which knows about any possible interactions between the modules it services. The new subsystem allows for a flexible representation of the underlying hardware (e.g.: the power management unit of the WCN/QCA chips is the device node to which the power sequencer binds but on the device-tree it is represented as a PMIC exposing a set of regulators consumed by WLAN and Bluetooth nodes).
This talk will present the idea behind the new subsystem, the provider and consumer programming interfaces for drivers and how we enabled WiFi and Bluetooth support upstream for several Qualcomm platforms with the first driver based on the pwrseq framework.
[1] https://lore.kernel.org/netdev/20240528-pwrseq-v8-0-d354d52b763c@linaro.org/
The introduction of the new -Wflex-array-member-not-at-end compiler option, released in GCC-14, has revealed approximately 60,000 warnings in the Linux kernel. Among them, some legitimate bugs have been uncovered.
In this presentation, we will explore in detail the different strategies we are employing to resolve all these warnings. These methods have already helped us resolve about 30% of them. Our ultimate goal in the Kernel Self-Protection Project is to globally enable this option in mainline, further enhancing the security of the kernel in the spatial safety domain.
As this is a work in progress, the main goal of this presentation is to gather feedback from the wider community of kernel developers to further improve our strategies and effectively address the remaining issues.
Modified condition/decision coverage (MC/DC) is a fine-grained code coverage
metric required by many safety-critical industrial standards, including
aerospace, automotive, medical and rail. It is challenging to measure MC/DC of
targets as complex as Linux kernel. We will discuss our effort on measuring
MC/DC of Linux and the opportunities it would open up. The main challenges are
toolchain support (both LLVM and GCC added MC/DC capability just recently) and
kernel support for persistent coverage profile data. We have been working on
quality assurance of LLVM MC/DC implementation using both the Linux kernel and
other real-world software projects. We have also developed kernel support for
MC/DC measurement, by reusing a part of an early patch set originally intended
for profile-guided optimizations. We will present our early results on MC/DC of
Linux and avenues towards rigorous kernel testability from existing test
harnesses like KUnit and kselftest.
Repo: https://github.com/xlab-uiuc/linux-mcdc
KernelCI started 10 years ago as a small project to test the kernel on Arm devices. The project grew over the years and today a new architecture is in place. In this talk, Don and Gustavo will present you the new KernelCI. The KernelCI community put a lot of effort recently to design and implement its new testing architecture with a focus on facilitating the kernel community and industry engagement as much as possible.
Our new KernelCI Architecture (1) allows different services(such as patchwork, b4, etc), multiple CI services, and users to send request to test patches; (2) supports all sorts of testing platforms and hardware labs, not just embedded hardware; (3) focus on quality of test run, rather than quantity; (4) brings common database for all CI systems with automatic post-processing of regressions.
How to track existing LTP tests for a set of syscalls to their man pages and spot gaps?
How can the community be notified by a change to the kernel source code or to the man page?
How to provide a Test environment that is integrated in an automated CI workflow?
We'll discuss how BASIL can answers some of these questions.
Duplicated symbol names in kallsyms pose challenges for tracing and probing operations in the Linux kernel environment, complicating system observability and debugging.
To tackle this issue, kas_alias is introduced, a new tool added to the kernel build process to identify duplicated symbols and add aliases to them, ensuring existing workflows remain unaltered.
kas_alias operates on intermediate build products, specifically the binary objects, to analyze symbol name frequencies.
It then generates aliases for duplicated symbols and integrates them into both the core image and module objects.
In summary, kas_alias offers a practical solution to the challenge of symbol name duplication, enhancing system observability and debugging capabilities without introducing unnecessary complexity.
LKML discussion
Some kernel mitigations are very expensive, some others fail to adequately address classes of vulnerabilities. At the same time it is hard for users to make informed cost/benefit decisions about whether to enable a particular mitigation or not.
This presentation critically assesses a handful of past and upcoming security mitigations, proposing a data-driven evaluation of their impact on security, performance, and attack surface. We discuss lessons learned from Google's Kernel CTF and the importance of threat modeling for choosing the right kind of mitigation.
Device links have been around for a while now, but not used extensively/effectively until fw_devlink was implemented and improved over the last few years. fw_devlink is finally in a fairly stable state where it can correctly handle cyclic dependencies and also break the cycle.
With all the additional device dependency tracking info that's available in the kernel, the community can improve how we handle boot up, suspend/resume, device/driver deregistration and system shutdown, etc.
This talk intends to catch the community up on the current status so we:
Embedded System-on-Chips (SoCs) provide unique, device-specific keys for encrypting and decrypting user data, serving as a Root of Trust (ROT) store crucial for security. Historically, the Trusted Keys framework in the Linux Kernel was tightly integrated with Trusted Platform Module (TPM), limiting the ability to incorporate additional sources of trust like Trusted Execution Environments (TEE). Starting from v5.13, the Kernel now supports a flexible Trusted Keys framework, enabling the integration of various underlying trust sources. Initial efforts have integrated TPM and TEE into this framework.
Over the last three years, significant progress has been made with the addition of hardware sources of trust such as CAAM and DCP (introduced in 6.10). This presentation dives into the evolution of trusted keys, current framework capabilities, and supported trust sources (TPM, TEE, CAAM, DCP). It also outlines ongoing efforts, planned for v6.12, to incorporate Hardware Unique Keys (HUK) for STM32 platforms. Additionally, the talk explores the implementation of the trusted keys retention service in the Kernel, including applications in DM-Crypt and fscrypt from userspace.
I would like to propose a BoF in honor of Daniel Bristot de Oliveira. I'd like it to be held on Thursday night after the last session, so that all can attend. I may even look to see if it is possible to serve refreshments (beer and wine), that would be paid for by those willing to donate. People would be able to come up and give stories about their memories of Daniel. The purpose of this BoF is to celebrate Daniel's accomplishments and how he has left a lasting positive impression on our community.
The Power Management and Thermal Control microconference is about all things related to saving energy and managing heat. Among other things, we care about thermal control infrastructure, CPU and device power-management mechanisms, energy models, and power capping. In particular, we are interested in improving and extending thermal control support in the Linux kernel and utilizing energy-saving features of modern hardware.
The general goal is to facilitate cross-framework and cross-platform discussions that can help improve energy-awareness and thermal control in Linux.
Since the previous iteration of this microconference, several topics covered by it have been addressed, including:
https://lore.kernel.org/linux-pm/6017196.lOV4Wx5bFT@kreacher/
https://lore.kernel.org/linux-pm/20240223155942.60813-1-stanislaw.gruszka@linux.intel.com/
https://lore.kernel.org/linux-pm/20240117095714.1524808-1-lukasz.luba@arm.com/
https://lore.kernel.org/linux-pm/20240109094112.2871346-1-daniel.lezcano@linaro.org/
https://lore.kernel.org/linux-pm/20240109094112.2871346-2-daniel.lezcano@linaro.org/
and there is work in progress related to some of them:
https://lore.kernel.org/linux-pm/20240119110842.772606-1-abailon@baylibre.com/
https://lore.kernel.org/linux-pm/20240127004321.1902477-1-davidai@google.com/
This year we will mostly talk about thermal control subsystem enhancements, including user trip points and PID thermal governor, thermal and performance control interfaces for devices, system suspend support enhancements and power/energy estimation tooling.
For the last year the thermal control subsystem in the Linux kernel has been undergoing an extensive redesign resulting in some code simplifications, enhancements and fixes for known issues. However, there are still ways to improve it. Among other things, the following changes may be considered:
I would like to discuss all of these possible changes in order to set the direction of development.
The trip points are used by the kernel to start mitigating a specific thermal zone when a temperature crosses this limit. This action is taken to protect the silicon. The userspace thermal management has a more complex logic where it takes into account multiple sources of information like the temperatures, the usage and the current application profile to sustain the performance. It readjusts the different components performance given the temperatures of some certain zones. In order to monitor the temperature, it has to get notified when a specific temperature is reached and must change the temperature constraint to get new notification. The notification is the preferred way because it does not prevent the system to go to a deep idle state. However, there is no such a mechanism in the kernel and the userspace tricks the writable trip points to achieve this goal. Unfortunately this is fuzzy for different reasons and can lead to inconsistencies.
The goal of the discussion is to put on the table those inconsistencies and discuss proposals to have the userspace dealing with thermal notification gracefully.
The step wise governor is largely used by all mobile platforms. Those are more and more performant, so overheating very quickly. Given the speed of the temperature transitions, the step wise governor does not have enough time to apply the right cooling effect as it must go through several iteration to reach the temperature drop. Several iterations means hundreds of milliseconds. During this time, the temperature can cross way too much the temperature limit or can decrease the performance. Those are known as overshoots and undershoots. On the other side, the power allocator governor applies a PID loop with power values to mitigate the temperature. This PID loop allows to flattened the temperature figure at mitigation time, thus preventing the overshoots and undershoots. Unfortunately, power numbers are not available most of the time and this governor is not usable without them.
The proposal is to provide a simplified PID governor to handle the mitigation which don't have power number but with high temperature speed.
The userspace which has a complex logic to manage the thermal envelope of the platform is often platform specific because custom kernels export clumsily interfaces to act on PM. Therefore, the userspace is often unusable when we want to support mainline kernels. That leads to more work as there are multiple userspace implementation to achieve the same goal. The objective of the discussion / proposal is to agree on interfaces we can use to have generic mechanism in userspace to act on performance, thermal and power without a knowledge of the hardware the logic is running on.
As a community, we pay a lot of attention to the performance impact of the changes we land. Especially when it comes to areas like scheduler/cpufreq that are expected to have a significant impact on performance. This is possible because we have good benchmarks to quickly iterate over and check the impact of our patches.
However when it comes to checking the power/energy impact of our changes, the tooling is sorely lacking.
You either have to remove the battery and attach the device to some external power supply that measures the power/energy it's providing OR hope for internal coulomb counters in the board OR just go with the very granular battery % reported by the device. All of these options are either cumbersome or not easy to iterate with or easy to acquire.
To address this gap, we've developed Wattson.
A tool that can use tracing info to fairly accurately estimate the % change in energy consumption caused by a patch and even allow the developer to sort the threads by the energy consumption/impact. This will allow us to quickly iterate and sanity test the impact of patches without having to depend on specialized hardware setup and avoid environmental noise (more on this in the talk).
In this talk, we'll show what we've achieved so far, how the tool could be used and the advantages and caveats of the Wattson. We'll also take any feedback on how the tool could be made more friendly for the community.
Optimizing suspend/resume time makes a significant difference for UX
and power savings. Especially for wearable devices which typically
have small CPUs and small batteries. This talk will point out all the
gaps we've found so far and what we could do to address them and some
of my TODOs to get there.
On legacy platforms it's common to support suspend-to-ram (S2R), but not suspend-to-idle (S2I). In many cases, this seems to be because of some limitations in the FW that deals with CPU power-management.
For various reasons, we want to promote S2I in favor of S2R due to the benefit it provides, but it's not always possible to convince vendors to update their FW for legacy platforms.
In a way to improve the situation, let's discuss the problems and the potential options we have at the kernel side, to enable support for S2I for these legacy platforms.
The eBPF Track is going to bring together developers, maintainers, and other contributors from all around the globe to discuss improvements to the Linux kernel’s eBPF subsystem and its surrounding user space ecosystem such as libraries, loaders, compiler backends, related system tooling as well as eBPF use cases.
The gathering is designed to foster collaboration and face to face discussion of ongoing development topics as well as to encourage bringing new ideas into the development community for the advancement of the eBPF subsystem.
The track will be composed of talks, 30 minutes in length (including Q&A discussion).
eBPF Track's technical committee: Alexei Starovoitov, Daniel Borkmann, Andrii Nakryiko and Martin Lau.
Over the past ten years, many fuzzers have been written specifically for the BPF subsystem. They follow diverse strategies, either porting the verifier to userspace [1, 2], describing the BPF syntax in details [3, 4], or devising new test oracles [5, 6]. Several such fuzzers have uncovered bugs and vulnerabilities, but none has a very good coverage of the whole BPF subsystem.
This talk will compare the various BPF fuzzing strategies, with their scope, strengths, and weaknesses. We will then focus on the syzkaller fuzzer, which has the broadest scope and most up-to-date descriptions, to highlight areas of BPF that have received less attention. The aim of this talk is to discuss approaches to improve the status quo.
1 - https://github.com/iovisor/bpf-fuzzer
2 - https://github.com/atrosinenko/kbdysch
3 - https://github.com/google/buzzer
4 - https://github.com/google/syzkaller
5 - https://dl.acm.org/doi/10.1145/3627703.3629562
6 - https://www.usenix.org/conference/osdi24/presentation/sun-hao
In 2023, we open sourced buzzer: A library to construct random, syntactically valid, eBPF programs, with the objective of validating the security assumptions of the verifier. Since then we have also developed new features into buzzer like coverage tracking and support for things like function calls and BTF.
The purpose of the talk is to share some of the lessons learned, what did/didn’t work when finding the CVEs buzzer has discovered and what angles of eBPF could be fuzzed in the future.
While eBPF has been used in various scenarios, it presents two issues in use. The first is the complexity issue, where legal programs may fail in the verification due to the verifier’s limited capabilities. Researchers have resorted to ‘’verifier-oriented programming‘’ to circumvent this issue, such as masking memory accesses to reduce the verification complexity. Even so, it remains a persistent issue highlighted by many literature; The second is the security issue, where malicious programs may pass the verification due to vulnerabilities. Over half (36/60) of eBPF’s CVEs come from the verifier since 2014.
Through systematic analysis, we found that the above issues come from the full-path analysis stage of the verification. It executes symbolically the program at the entry and explores all possible execution paths to check whether the state is illegal or not. However, it encounters the well-known state explosion problem, which has become the bottleneck of eBPF.
This proposal aims to address the above challenges to expand the practical applications of eBPF. Specifically, current BPF programs are viewed as part of the kernel code, so eBPF uses the verification-based method to “review” the code to identify all abnormal behaviors. But we choose another perspective — BPF programs are a new type of kernel-mode application that interacts with the kernel through helper function calls rather than system calls, so kernel security should be achieved by isolating BPF programs, not by verification. As such, we aim to build an isolated execution environment for eBPF and enforce runtime isolation for BPF programs, thus eliminating the need for full-path analysis in the verification.
First presented to the community at Linux Plumbers 2023 [1], Agni is a tool designed to formally verify the correctness of the verifier's range analysis. Agni automatically converts the verifier's source code into an SMT problem, which is then fed into the Z3 solver to check the soundness of the range analysis logic.
This talk will provide an update on Agni's recent developments. In particular, a year ago, Agni would need several hours to several weeks to verify the soundness of the range analysis for all instructions. Thanks to a new, modular verification mode, Agni's runtime has been reduced to minutes in most cases.
This significant improvement allowed us to build a CI where Agni is regularly run against various kernel versions (including bpf-next). Finally, we will discuss the remaining milestones before we can consider a better integration of Agni with the BPF CI.
1 - https://lpc.events/event/17/contributions/1590/
This talk will present our approach to enhancing the eBPF verifier's precision: lazy abstraction refinement with proof. We will begin by discussing the fundamental sources of imprecision in the current verifier and reviewing relevant efforts towards these issues. Next, we will show how a proof-based approach can potentially improve precision without introducing much complexity. We achieve this by (1) utilizing the existing abstract interpretation as much as possible to benefit from its efficiency, i.e., being lazy, (2) refining the abstraction with a more precise technique when it is too coarse-grained, allowing the verifier to continue the validation, (3) encoding the refinement in a machine-checkable proof, which is accepted only after linear-time validation. In essence, proofs generated in user space and validated in kernel space ensure minimal overhead.
This work is in its early stages, and we look forward to sharing our central idea and receiving valuable feedback.
Despite its vast use in the BPF verifier, tnum (tristate numbers or tracked numbers, i.e. var_off field in struct bpf_reg_state) remain less understood compared to its more intuitive min/max counter parts, and for good reason (also perhaps to its own peril) — it works very well and comes with a comprehensive set of APIs; leaving little reason for further mangling and learning.
Nevertheless, good code should be read and understood. More importantly, there could never be too many reviewers when it comes to the safety-critical value tracking logic. As such, this talk aim to discuss tnum in depth, covering:
- concepts
- how it works (i.e. implementation)
- limitations
- explanation of (some) existing operators
- how its used
- related bugs
- crafting operator from scratch
- testing & verification
The goal is that by the end of the talk, the audience will feel much more confident when it comes to reasoning, reviewing and writing tnum-related code.
bpftrace is a popular and powerful dynamic tracer for Linux systems. In the vast majority of uses cases, bpftrace does its job quickly, efficiently, and accurately. However with the rapid increase of users, use cases, and features, the bpftrace community has started to feel (technical) growing pains. In particular, we've started to uncover various reliability issues. In this talk, we will cover what is already done as well as what is currently broken and how we will systematically fix and prevent these issues from reoccurring.
bpftrace is a popular, BPF-powered tool for observability of both the kernel and userspace. It comes with a domain-specific language, bpfscript, which it compiles into BPF bytecode.
In the past year, bpftrace modernized the way it creates BPF programs by making the emitted BPF ELF objects compatible with libbpf's bpf_object. This allows bpftrace to use modern BPF features such as subprograms, relocations, or global variables.
In this talk, we will walk you through the most important steps and help you understand what are the obstacles and challenges of creating a custom BPF front-end which is compatible with state-of-the-art BPF technology, using libbpf as the back-end.
Along the journey, we also ran into several issues and missing features in libbpf. We would like to discuss them with the community and propose potential solutions.
Bpf provides ability to trace kernel functions (kprobe, kretprobe, fentry and fexit) and users often use such features to do kernel function tracing in order to gather information for their particular needs. But compiler optimization may make kernel func tracing difficulty. For example, complete inlining may make function going away in symbol table. Partial inlining may leave functions in certain original call site but not others. Compiler may also make changes to function parameters or introduce suffix to original function name in order to signal scope/functionality change for those functions. In this talk, we will discuss different cases how compiler optimization impacts kernel function tracing and if possible how to cope with them.
There have been many improvements in reducing the overhead associated with user-space probes (uprobes) such as using system calls instead of traps to fire the probe. However it remains the fact that there is significant overhead associated with uprobe firing. Add to this that in many tracing cases, the predicate associated with the probe is negative;
etc. In such cases we still need to trap or syscall into the kernel to run the BPF program that evaulates those predicates. However, with a combination of a memory-mapped BPF map (storing the "foo" or the 1234 for comparison) and a vDSO-like experience (where tgids, uids etc are cached in a memory-mapped map such that no syscall is required to retrieve them), many such predicates could potentially be evaluated fully in userspace. This would mean that in the negative predicate case a trap/syscall would not be required, limiting overhead for uprobe attachment to cases where in-kernel execution is required. We would need a way of JITing to a userspace-only program along with a mode of attachment that worked system-wide for userspace programs. Many of the helpers would be JITed to a vDSO retrieval (e.g. bpf_get_current_pid_tgid()).
Exploring BPF-based vDSO in its own right is also interesting, since BPF can overcome some of the issues with simple caching of values (since it can catch events that invalidate cached values and update them), but the added selling point of facilitating user-space only tracing makes this a potentially interesting area for exploration with the community.
BPF LSM enables implementing flexible security policies without rebuilding the kernel. However, the flexibility and safety of BPF LSM comes with the limitation that not all kernel functions are available to the BPF programs. The answer to this limitation is BPF kfuncs. Since LPC 2024, a few important kfuncs are added (or being added) for BPF LSM use cases. [1][2][3]
In this talk, we would like to discuss proposals to add more kfuncs for BPF LSM. We will start with some real world use cases, and discuss how to implement the policies properly with BPF LSM and kfuncs.
[1] https://lore.kernel.org/bpf/20231129234417.856536-1-song@kernel.org/
[2] https://lore.kernel.org/bpf/20240730230805.42205-1-song@kernel.org/
[3] https://lore.kernel.org/bpf/20240731110833.1834742-1-mattbobrowski@google.com/
An quick intro to infrared on Linux, and introduce new tool called cir
Intro needed for context of what we're trying to do with finite automations.
https://github.com/seanyoung/cir
Show how to use finite automations to generate efficient BPF code
Compiles IRP mini language to BPF (in a single binary/process, written in pure rust).
I think it is interesting because:
CFP closes on July 15th.
Unlocking the Future of Open-Source Camera Software
The camera hardware landscape has undergone a dramatic transformation, moving from simple frame producers to highly configurable and programmable systems. Unfortunately, open-source camera software has struggled to keep pace, creating a bottleneck that hinders innovation and limits the potential of modern camera technology.
This microconference will bring together key stakeholders to address the urgent challenges and opportunities in open-source camera software development.
Call for Proposals:
We invite proposals for topics in the following and related areas:
Who Should Attend:
Microconference Format:
The microconference will consist of short discussion topics, introduced and moderated by the participants. Each topic lead is expected to prepare a short presentation that will be shared with all the attendees in advance so we can use the Micro Conference for questions and face to face discussions.
After the conference we will divide in smaller working groups.
Submission Deadline: 15th July 2024
We look forward to your contributions in making complex cameras a reality in Linux!
The Complex Camera Summit will be held just before Plumbers. For a whole day Vendors, Distros and Kernel Maintainers will have discuss the future of Complex Cameras in Linux, covering kernel APIs and userspace camera stacks.
During this presentation we will report the conclusions of that meeting to the rest of the community, gather feedback and discuss open questions.
Allocating shared buffers between disparate hardware devices remains a significant challenge in modern systems. The diverse constraints of each device make it difficult to find allocation strategies that are both efficient and universally compatible. Current solutions often rely on ad-hoc workarounds and duct-tape.
This session aims to foster discussion on best practices for efficient memory allocation. We will explore the key challenges, potential approaches, and the need for more standardized, robust solutions.
Vendor Passthrough mechanisms enable direct communication between userspace and hardware devices, fully or partly bypassing traditional kernel software stacks. This approach has found applications in various subsystems, such as testing new protocols (e.g. NVMe Passthrough), debugging hardware, and implementing user-space drivers (e.g. DPDK). Some subsystems have set stricter rules governing the userspace portion of the stack (e.g. DRM).
The camera domain has traditionally been cautious about accepting undocumented pass-through APIs. This session aims to explore the needs for different types of pass-through options for complex camera systems, and their potential benefits and risks. We will seek to gather insights from the experiences of other subsystems that have considered or utilized this technology.
The Containers and Checkpoint/Restore micro-conference focuses on both userspace and kernel related work. The micro-conference targets the wider container ecosystem ideally with participants from all major container runtimes as well as init system developers.
The microconference will be discussing recent advancements in container technologies with some of the usual candidates being:
On the checkpoint/restore front, some of the potential topics include:
And quite likely a variety of other container and checkpoint/restore topics as things evolve between now and the event.
Past editions of this micro-conference have been the source of many developments in the Linux kernel, including:
Processes can not enter into pre-existing process-session (sid), sessions can
only be inherited. (Same for process-groups (pgid) in nested pid namespaces.)
Probable solution 1 - CABA:
The idea was to save as much of the original historical tree topology as
possible in an auxiliary in-kernel tree, but it didn't go well. I also have
the same thing in eBPF but obviously it is unreliable.
See my previous talk on this matter with a deeper dive.
Probable solution 2 - Allow setsid to pre-existing session + Allow setsid/setpgid to "sid 0":
Is it safe? - We can prohibit entering into a session with controlling ttys, so
that there is no way someone can use this change to steal your passwords.
Because, for pid namespace init creation, we need at the same time:
a) be checkpoint_restore_ns_capable at all levels of pid namespace’s owner
user namespaces;
b) be inside user namespace which is an owner of the pid
namespace to be created;
Probable solution 1 - Hack clone3 syscall to receive second user namespace (b) somewhere in arguments.
Probable solution 2 - Make it possible to create a pid namespace separately from creating its init, create init through setns:
Here we need to carefully handle races of two processes created at the same
time in a not yet fully setup pid namespace.
If we have different cpu features returned by cpuid (or different xsave
features/sizes) between nodes, we can not migrate a process between those
nodes as glibc of the process may have detected cpu features on the first
node and will try to use these features after migration even if the feature
is not available on the destination.
Probable solution - Do it like in OpenVZ:
Using cpuid faulting cpu feature to return restricted cpuid mask for containers
(need to patch kernel).
Container checkpointing has recently been enabled in orchestration platforms like Kubernetes, where the smallest deployable unit is a Pod (a group of containers). However, these platforms are often used to deploy distributed applications running across multiple nodes, which presents a new challenge: How to create consistent global checkpoints of distributed applications running in multiple containers across different cluster nodes?
To address this challenge, we developed criu-coordinator — a tool that synchronizes checkpoint and restore operations among multiple CRIU instances to enable coordinated checkpointing for distributed applications. This talk will cover the design and architecture of criu-coordinator, and discuss its integration with existing container platforms.
Containers are a user space fiction, there is no single container concept within the Linux kernel and what set of components constitutes a container isn't something we expect everyone to agree on any time soon (if ever).
That said, we've seen many ask for ways to easily figure out whether a process belongs to a container, if so, which one, who/what's responsible for it, ...
Some of the existing tools like ps/top rely on some clever parsing of the cgroups used by the process to figure out what container they may belong to. Others walk the entire process tree and keep track of what spawned a particular process tree.
But again, there is no guarantee that a particular container implementation will use cgroups, or will use an easily detectable parent process for the container's tree.
A few years ago, there was a proposal by José Bollo to introduce the concept of process tags (ptags) as a LSM.
While this apparently didn't really go anywhere, the general idea is interesting and would likely be a good generic solution to solve this recurring problem.
Effectively having support for key/value storage of data as part of a process with a number of restrictions on top of it to make it safe and useful:
- Tags are copied to children at clone time
- A tag can never be removed
- The value of a tag can never be altered
- Tags can only be set by root (of namespace) or the process' owner
- Tags are owned by whoever created them
- The number of tags and the length of their value is restricted
This session will attempt to answer:
- Does this solve the usual "what container is this?" question
- Any other use cases for this mechanism?
- Is there something already present today we could rely on instead?
- Are there specific concerns around security or performance of something like this?
This talk is about a problem of integration between the concept of an "isolated" ([1], [2], [3], [4]) user namespace and cgroup-v2 delegation model.
The biggest challenge here is that cgroup delegation is based on cgroupfs inodes ownership and cgroupfs superblock is shared between all containers which makes it impossible to deal with cgroupfs as with any other containerized filesystem like procfs or tmpfs.
[1] More flexible user namespaces https://fosdem.org/2024/schedule/event/fosdem-2024-2987-more-flexible-user-namespaces/
[2] User namespaces with host-isolated UIDs/GIDs https://lpc.events/event/17/contributions/1569/
[3] Isolated dynamic user namespaces https://lpc.events/event/7/contributions/836/
[4] Simplified user namespace allocation https://lpc.events/event/11/contributions/982/
With the introduction of extensible-struct syscalls such as openat2 and clone3, the inability to usefully filter syscalls with pointer arguments makes it harder for various programs to make use of newer kernel features because of both default container and self-hardening seccomp profiles. The inability for systemd and other system utilities to use RESOLVE_IN_ROOT and related openat2 features is a particular issue.
This talk will describe a proposal for an extension to seccomp to allow for the filtering of extensible-struct syscalls on an opt-in basis, as well as some of the potential issues with creating forward-compatible filters due to the restrictions of cBPF and some possible solutions.
PuzzleFS is a container filesystem designed to address the limitations of the existing OCI format. The main goals of the project are reduced duplication, reproducible image builds, direct mounting support and memory safety guarantees, some inspired by the OCIv2 brainstorm document.
Reduced duplication is achieved using the content defined chunking algorithm FastCDC. This implementation allows chunks to be shared among layers. Building a new layer starting from an existing one allows reusing most of the chunks.
Reproducible image builds are achieved by defining a canonical representation of the image format. Direct mounting support is a key feature of PuzzleFS and, together with fs-verity, it provides data integrity. Currently, puzzlefs is implemented as a userspace filesystem (FUSE). A read-only kernel filesystem driver is available as a POC.
Lastly, memory safety is critical to PuzzleFS, leading to the decision to implement it in Rust. The same code is shared between user space and kernel space in order to provide one secure implementation.
The author will present the integration of PuzzleFS into the OCI Image Specification, demo a PuzzleFS workflow and discuss further integrations with LXC and stacker.
One question applications running in containers often ask is: how many CPUs do I have access to? They want to know, e.g., how many threads they can run in parallel for their threadpool size, or the number of thread-local memory arenas.
The kernel offers many endpoints to query this information. There is /proc/cpuinfo, /proc/stat, sched_getaffinity(), sysinfo(), the cpuset cgroup hierarchy's cpuset.cpus.effective, the isolcpus kernel command line parameter, /sys/devices/system/cpu/online. Further, libcs offer divergent implementations of sysconf(_SC_NPROCESORS_ONLIN). As a bonus, the kernel scheduler may be configured to limit resources using cpu "shares" or cpu quotas, so a task may be able to run on all cores, but have some kind of rate limit that is not reflected in the physical cores the system is allowed to run on. Or, if SCHED_EXT lands as expected in 6.11, this whole concept will be configurable in userspace.
This discussion is an extension of one that began at FOSDEM'24 1, where we proposed a rust library for users to link against that would contain this information. In the hallway track of that conference, we ended up talking with systemd folks, who asked for an RFE2 for a /var/link interface so that this could be determined by IPC instead of by library.
There are advantages and drawbacks to both approaches. A library will require all language runtimes to modify their builds and add dependencies, which will be a tough sell. An IPC mechanism will require containers to be running this code, or the host running the code. In the IPC case, is some question about the container's cgns and resolving this stuff below the delegation boundary.
The goal of this talk will be to come away with a decision on a path forward.
Some users of systems with many cgroups may notice that things don't work as swiftly as with fewer cgroups. One part it is caused by simply greater amount of data that must be processed at higher hierarchy levels, another part is that more cgroups mean more frequent operations that affect the running system.
In this talk, I sum up changes from roughly past two years done to better cope with large cgroup trees and trade-offs they brought about. Consequently, I describe places that still can have negative effects with growing number of cgroups. In the conference, I'd like to discuss issues like this and preferences when the tradeoffs are to be resolved.
Enterprise users are likely one of the last holdovers still running cgroup
v1. As they continue to transition to cgroup v2, we would like to discuss
the deprecation (and potentially deletion) of cgroup v1.
In 2022 [1], systemd proposed the removal of cgroup v1 support from systemd,
but the community wasn't (yet) ready.
Work has already begun in the kernel to isolate cgroup v1 [2] in the memory
subsystem.
We would like to have an open forum to discuss the deprecation of cgroup v1
from all of Linux. Applications can't make these decisions in a vacuum
because there are so many interdependencies. The Containers and
Checkpoint/Restore LPC microconference may have the greatest representation
of the various interested parties, and we would like to leverage this to start
the discussion.
Areas of discussion:
* Is there any plan to isolate the cgroup v1 code in other controllers
(similar to the work that was done for the memory controller)
* What applications don't support cgroup v2? How do we get them there?
* Previously, v2 containers on a v1 host (or vice versa) was a point of
contention. Does this issue go away as older distros reach EOL?
* RHEL7 (cgroup v1) has reached EOL in summer of 2024
* Oracle Linux (OL) 7 (cgroup v1) reaches EOL in December of 2024
* Note that OL8 still defaults to cgroup v1 and its EOL is 2029 :(
* I'm afraid of the "unknown unknown" dependencies and interactions.
Is there anything we can do to plan and prepare for these?
* Can we come up with a roadmap or timeline for EOL'ing cgroup v1 across the
board?
We plan on bringing a list of distros, kernels, applications and their cgroup versions and EOL dates.
[1] https://lists.freedesktop.org/archives/systemd-devel/2022-July/048120.html
[2] https://lore.kernel.org/all/20240625005906.106920-1-roman.gushchin@linux.dev/
Use-cases: userspace tracing ring buffers, userspace memory allocators
(e.g. tcmalloc), statistics counters.
Discuss proposal: Introduce a new cpu.max.concurrency interface file
to the cpu controller, which defines the maximum number of
concurrently running threads for the cgroup. Track the number of CPUs
concurrently used by the cgroup. Extend the scheduler to prevent
migration when the number of concurrently used CPUs is above the maximum
threshold.
We are excited to propose the next edition of the RISC-V micro conference to be held during the Plumbers Conference in 2024. This event has consistently served as a pivotal gathering for developers, enthusiasts, and stakeholders in the RISC-V ecosystem, especially those focused on its integration and evolution within the Linux environment. Broadly speaking anything related to both Linux and RISC-V is on topic, but discussion tend to involve the following categories:
Possible Topics
The actual list of topics tends to be hard to pin down this early, but here's a few topics that have been floating around the mailing lists and may be easier to resolve real-time:
Key Stakeholders
Apologies if I've missed anyone, but I've tried to list a handful of the people who frequently show up and help drive discussions at the RISC-V microconferences we've held at past Plumbers:
Regular RISC-V contributors/maintainers (I probably forgot few more)
Accomplishments post 2023 Microconference
[1] https://lore.kernel.org/lkml/a49546e8-6749-4458-98da-67fd37b7df18@rivosinc.com/
[2] https://lore.kernel.org/lkml/20240325164021.3229-1-jszhang@kernel.org/
[3] https://lore.kernel.org/lkml/20240217005738.3744121-1-atishp@rivosinc.com/
[4] https://lore.kernel.org/lkml/20240112111720.2975069-1-cleger@rivosinc.com/
[5] https://lore.kernel.org/all/20240115055929.4736-3-andy.chiu@sifive.com/t/#m1d48afa31c6040e4433cbf3bae2de998ae2ca112
Unified discovery is bad and should stay out of the kernel. I'm just going to have a single slide saying that.
RISC-V Linux goes out of its way to consider overlapping-ISA heterogeneous multiprocessing when managing extensions. Let's review and discuss the current extension support to ensure there aren't gaps nor unnecessary burdens.
The upcoming series of ftrace code patching reduces the reach of each patch-site to a +/- 2KB range. This might be the unavoidable option we must take, as we move on to wave stop_machine() away, support preemption, and maintain an acceptable code size. Thus, we are going to focus our discussions on what options are there for us to support direct calls and various ftrace optimizations. Besides, we would like to collect requirements for generic code patching, and discuss any possible ways for us to do atomic code patching generally.
Some discussion items:
- Should we require such a general extension name ziccif for us to enable dynamic code patching?
- Can we reduce patch_text to patch_callsite? Is there any room for us to get rid of stop_machine under this assumption?
RISC-V IO Mapping Table (RIMT) is RISC-V specific ACPI table for providing the IOMMU information to the OS. This specification is currently in draft state and we have done PoC with qemu and linux. We would like to discuss linux changes required, the challenges and proposed solutions. The discussion would help greatly to freeze the specification.
APLIC is optional in RISC-V. ACPI doesn't have any mechanism to directly support MSIs or GSI to MSI mapping without an wired IRQ to MSI bridge. This proposal takes an attempt to solve that problem.
We have a had discussions on enabling control flow integrity on riscv for user mode in past. Most of the discussions on that front have settled. In this talk we will do quick recap of user mode cfi support status and considerations with respect to vDSO management and focus on single label scheme. We will be discussing CPU assisted kernel control flow integrity for risc-v kernel as well. We have a RFC patch [1] on enabling kernel cfi.
[1] https://lore.kernel.org/lkml/CABCJKuf5Jg5g3FVpU22vNUo4UituPEM7QwvcVP8YWrvSPK+onA@mail.gmail.com/T/#m7d342d8728f9a23daed5319dac66201cc680b640
The real-time community around Linux has been responsible for important changes in the kernel over the last few decades. Preemptive mode, high-resolution timers, threaded IRQs, sleeping locks, tracing, deadline scheduling, and formal tracing analysis are integral parts of the kernel rooted in real-time efforts, mostly from the PREEMPT_RT patch set. The real-time and low latency properties of Linux have enabled a series of modern use cases, like low latency network communication with NFV and the use of Linux in safety-critical systems.
This MC is the space for the community to discuss the advances of Linux in real-time and low latency features. For example (but not limited to):
Examples of topics that the community discussed over the last years that made progress in the RT MC:
Join us to discuss the future of real-time and low-latency Linux.
Ensuring temporal correctness of real-time systems is challenging.
The level of difficulty is determined by the complexity of hardware, software, and their interaction.
Real-time analysis on modern complex hardware platforms with modern complex software ecosystems, such as the Linux kernel with its userland, is hard or almost impossible with traditional methods like formal verification or real-time calculus.
We need new techniques and methodologies to analyse real-time behaviour and validate real-time requirements.
In this talk, we present a toolkit designed to evaluate the probabilistic Worst-Case Execution Time (pWCET) of real-time Linux systems.
It utilises a hybrid combination of traditional measurement-based and model-based techniques to derive execution time distributions considering variability and uncertainty in real-time tasks.
This approach provides assessment of execution time bounds and supports engineers to achieve fast and robust temporal prediction of their real-time environments.
Our framework models runtime behaviour and predicts WCET in a streamlined four-phase process: (1) model relevant aspects of the system as finite automaton, (2) instrument the system and measure latencies within the model, (3) generate a stochastic model based on semi-Markov chains, and (4) calculate pWCET via extreme value statistics.
This method is applicable across system context boundaries without being tied to specific platforms, infrastructure or tracing tools.
The framework requires injecting tracepoints to generate a lightweight sequence of timestamped events.
This can be done by existing Linux tracing mechanisms, for instance, BPF or ftrace.
Benefits include significantly reduced WCET measurement duration from days to minutes, dramatically accelerating development cycles for open-source systems with frequent code updates like Linux.
This efficiency doesn't compromise accuracy; our hybrid approach ensures robust temporal predictions, enabling developers to quickly assess real-time implications of changes and maintain system performance.
In our talk, we outline the steps taken towards this new evaluation method and discuss the limitations and potential impacts on the development process.
We invite interaction from the community to discuss the benefits and limitations of this approach.
Our goal is to refine this toolkit to enhance its utility for Linux kernel developers and maintainers, ultimately contributing to a more efficient and effective development process for real-time systems.
Did you ever run into a real-time application that implicitly did a malloc in its critical code path? Or used the wrong lock type? Or did you even wrote it yourself? Wouldn't it be nice to get an earlier warning about such mistakes? Dual kernels like Xenomai provide such a feature, not perfectly, but way better than "native" RT Preempt can currently provide. And if you as users of Xenomai why they do not use RT Preempt, this feature is one of the main reasons.
This session will explain why Xenomai can provide earlier feedback on real-time design violations and how it does that. It will then discuss if they are chance for RT Preempt to come up with something similar, where the maintenance challenges could be but also where there might be common ground with Xenomai.
rteval is a tool to help measure real-time latency
It does this by running a measurement module such as cyclictest that both measures latency and simulates a real-time application, while also running load modules that simulate non-realtime applications
Recently rteval has been undergoing a lot of development. These developments will improve the ability to measure and discover sources of latency and to simulate various scenarios a user might be interested in.
Firstly, rtla timerlat has been added as a measurement module. rtla is especially interesting for it's tracing capabilities which help to identify sources of latency in the kernel.
Secondly various means of partitioning machines are being added. Examples include isolcpus, cpusets, cgroups and full blown containers.
Thirdly various miscellaneous improvements such as the ability to employ power savings on cpus are being added.
We hope to use these changes to answer questions such as, can we achieve low latency if we are running a real-time application in one container and other applications in a different container? What kind of effect on latency does using cpu power savings have? What kind of results do we get in a worst case scenario, such as when running measurements and loads everywhere, and what kind of results do we get if tuning is allowed?
The current state of rteval and ongoing and future development will be discussed as well as the various uses of the tool.
Some kernel code implement a parallel programming strategy
that grabs local_locks() for most of the work, and then use schedule_work_on(cpu) when some rare remote operations are needed. This is quite efficient for throughput, since it keeps cacheline mostly local and avoid locks in non-RT kernels, paying the price when you need to touch a remote CPU.
On the other hand, that's quite bad for RT kernels, as touching other CPU's data will require that CPU to interrupt any RT task it's running in favor of executing the requested task, while the requestor CPU waits for it's completion.
To solve that, I propose a new QPW interface that harness the local_lock() -> spin_lock() implementation in PREEMPT_RT to avoid above mentioned interruption without requiring extra cycles in the hot-paths, and actually causing a major reduction in the time spent by the requesting task itself.
This presentation will show the idea behind the interface, and bring numbers on latency and throughput improvements for some of the potential users of this interface.
In the mission of reducing latency in KVM guests, we have seen a lot of missed deadlines caused by RCU core invocation, often causing guest exit only to have a timer interrupt invoking rcu_core() on host and causing a task switch.
While looking to improve that, it was noticed that no RCU lock is held in guest context, and thus it's possible to report a quiescent state in guest exit, avoiding the whole rcu_core() invocation.
In this presentation, there will be more details on how it was possible to improve both latency and throughput in the guest, presented with the numbers we got from standard tests.
Part of this work also caused the creation of a new RCU boot parameter that can reduce latency even in RT workloads ran in host context, which will also be discussed in the presentation.
CPU isolation allows us to shield a subset of CPUs from a lot of kernel interference, but not all of it. Activity on the housekeeping CPUs can and does trigger IPIs which can still end up targeting isolated CPUs. The main culprits here are static key updates and vunmap() + the resulting flush_tlb_kernel_range().
As discussed in previous editions, since these IPIs are only relevant to the kernel (and not to userspace), an approach to remove the interference is to defer these IPIs until the targeted (isolated) CPUs next enter the kernel.
This talk will present the changes that have happened since this was last presented, and open a discussion concerning the remaining challenges.
Proxy Execution has had a long history and has been worked on by many key scheduler developers and maintainers over the years. Because of this, when speaking at OSPM or Plumbers after picking up this work, I’ve often been very brief when covering the concept with the assumption that folks in the room often had more experience with it than I have.
However, I’ve found there are often a lot of basic questions about Proxy Execution that get asked after my talks, so I figured a talk providing some deeper background on why it’s needed, along with how it works and the various cases it needs to handle. We can also talk about some of the more complicated edge cases that have been worked out, allowing for questions as we go through it.
FIFO tasks may starve other non-RT tasks, which is mitigated by RT throttling.
Deadline servers have been introduced and are still under development as an alternative to mitigate and avoid starvation of non-RT tasks.
There is, however, the chance that some other FIFO tasks will be starved and that could lead to system deadlock.
I would like to open the discussion about the possibility of using deadline servers as a mechanism to prevent such situations and what conditions and policies would be acceptable by the community for such an implementation.
An overview of the current status of PREEMPT_RT. What patches are still not merged upstream, which will be dropped. What are the current shortcomings, which are currently addressed and in what way.
The Linux Fundation Techical Advisory Board (TAB) exists to provide advice from the kernel community to the Linux Foundation and holds a seat on the LF's board of directors; it also serves to facilitate interactions both within the community and with outside entities. Over the last year, the TAB has overseen the organization of the
Linux Plumbers Conference, advised on the setup of the kernel CVE numbering authority, worked behind the scenes to help resolve a number of contentious community discussions, worked with the Linux Foundation on community conference planning, and more.
This is an opportunity for people to find out more about the TAB and make suggestions about how the TAB or the Linux Foundation can better support Linux Kernel Development
The Android Micro Conference brings the upstream community and Android systems developers together to discuss issues and changes to the Android platform and their dependencies and interactions with the Linux kernel, allowing for collaboration on solutions for upstream.
Some highlights of progress made since last year’s MC:
For fw_devlink, got post-init-providers accepted into DT schema, as proposed and discussed at LPC. Additionally, as proposed at LPC, fw_devlink=rpm was made the default, so fw_devlink now enforces runtime PM ordering too.
After discussions last year on board-id property being used to pick a DTB by the bootloader, patches for a shared solution were submitted upstream.
Also, listening to feedback from last year, we are planning to have slightly longer slots, so talks are not so rushed, but that also means we will have to be even more selective with topics.
Potential discussion topics for this year include:
In pursuit of a stronger defense against kernel security issues, the Android ecosystem has been evolving since 2017 to more aggressively follow the upstream stable kernels. To support this evolution, the Android Common Kernel has been transformed from a reference kernel used primarily to cherry-pick features and security bug fixes into a binary release of a kernel that is kept up-to-date with the latest stable kernel releases and heavily tested by the entire Android community.
Now, there is an increasing emphasis on sustainability and reuse that has resulted in a need to prolong the support lifetimes of Android devices. This was underscored last year by the EU with the Ecodesign spec that requires phones and tablets to continue to receive feature and security updates for more than 5 years after they are purchased. We now see devices being sold with the promise of 7 or more years of updates. Even the 6-year support lifetime of some recent stable kernels are not long enough for modern devices which must now outlive the kernel that they launch with.
In this session we will discuss the next evolution of Android kernel support in the Android ecosystem to support device longevity.
The Android Open Source Project (AOSP) is an extremely attractive Linux-based stack for HMIs and all manner of richly-connected devices. Its ever expanding and industry-leading handset-grade feature-set, universally-known user experience and mostly permissive licensing make it a great fit for a large number of products. Despite all its benefits, however, keeping an AOSP-enabled device up-to-date over long-periods of time represents a significant challenge on a number of levels.
Given that the experiences involved with such endeavours varies a lot from device to device and from silicon vendor to silicon vendor, this session's purpose will be to present and discuss the collective experiences of several engineers that have, each in their own side, participated in such efforts over several AOSP releases. To that end, a live-streamed panel discussion with about half a dozen or more such practitioners is meant to be organized prior to LPC, thereby giving ample time for discussion outside the time constraints of an MC slot, and the aggregate wisdom of this exercise is meant to be presented at this session as part of the Android micro-conference.
AOSP is used in many different types of device, not just smart phones and tablets, but also digital advertising, white boards, building entry systems, and more. Consequently, there are a large number of AOSP developers, but where are they? It's like
the Fermi Paradox, but for software engineers. Contrast this with the community around, for example, the Yocto Project, which is active and vibrant
I would like to promote a discussion about what it would take to change this and create a community for AOSP devs. A community that is self sustaining and caters for all the players. Open source should lead to open development
Benefits: better understanding of problems and solutions; more productive developers; better quality AOSP products
Context I'm going to provide:
Potential discussion points:
Kernel supports default cma and system dmabuf heaps. In order to support protected usecase, additional heap types needs to be supported.
There are quite a few downstream dmabuf heaps maintained by vendors to support protected usecase. There is need to provide generic framework, which will reduce fragmentation of such dmabuf heap types.
The proposed restricted dmabuf heaps will support different allocation method ( SG, CMA etc) and access restriction methods.
This talk will cover the status of recent changes in Android and upstream related to memory control groups, planned work, and outstanding issues.
Here are some details:
PRODUCT_MEMCG_V2_FORCE_ENABLED or vendor overrides of cgroups.jsonmemcg v1 is now officially on the deprecation path: https://lore.kernel.org/all/20240625005906.106920-1-roman.gushchin@linux.dev/
Therefore it is likely memcg v2 will be default in Android 16, and memcg v1 will not be configured into the Android kernel.
Need to fix incorrect reporting of v2 controller counts: https://lore.kernel.org/all/20240528163713.2024887-1-tjmercier@google.com/
(Does anyone need / want this hierarchically instead of root-only?)
Android's transition to 16kb page sizes necessitates a comprehensive overhaul of device components to ensure seamless compatibility and optimal performance. This presentation will delve into the critical modifications required across the entire software stack:
Target audience: For Android partners aiming to launch devices with 16kb page size support.
This presentation delves into the ongoing upstream work: ublk zero copy based io_uring effort:
https://lore.kernel.org/io-uring/06c5f635-b065-4ff1-9733-face599ddfe3@gmail.com/T/#m6c99306b44992ee8fc12ad4e9d7a28cd59e081bb
The talk will focus on:
1: Why ublk zero copy is required in Android and how it will be used. Will explore the use cases that necessitate the implementation of ublk zero copy.
2: Walk through the I/O traces and discuss the prototype of the ongoing upstream patch with performance numbers and other caveats.
OPPO has deployed ARM64 CONT-PTE-based large folios (mTHP) on millions of real phones and is committed to contributing the code to Linus' tree, GKI, and the open-source community.
This topic will primarily discuss the opportunities and challenges encountered by OPPO in memory allocation, memory reclamation, LRU, and mTHP compression/decompression in zsmalloc/zRAM during the deployment of mTHP. We will introduce the mTHP software architecture and components deployed in OPPO products, explaining why we ultimately chose this architecture.
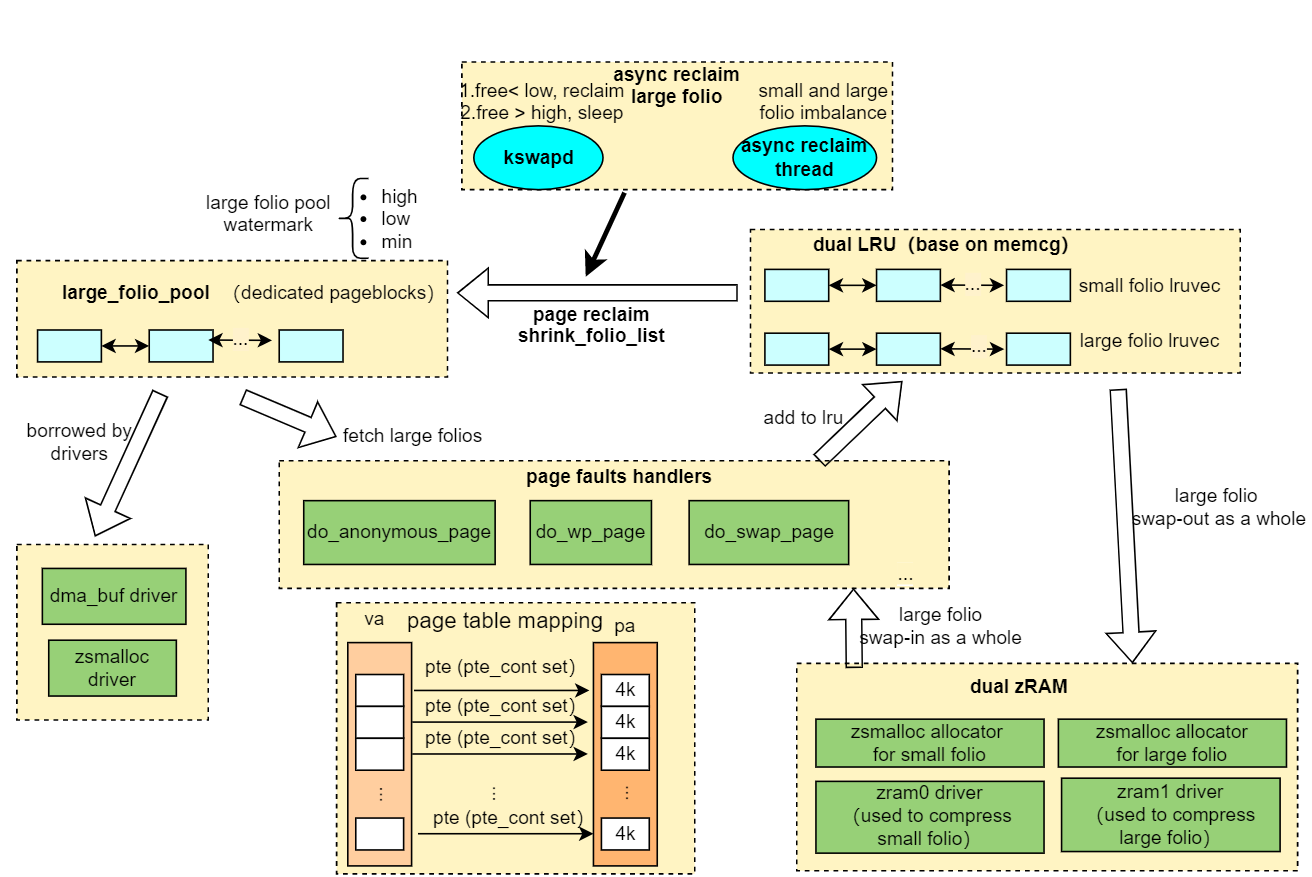
The topic will also highlight the performance gains achieved by leveraging large folios on Android phones.
Additionally, it will introduce several ongoing projects in the mm community that could replace OPPO's out-of-tree code and offer more general solutions that might eventually be merged into Linus' tree.
Birds of Feather session around Devicetree in Linux kernel. Few topics from the top of my head:
1. Devicetree and firmware-abstracted hardware. Fore example consider some resources like clocks and regulators hidden behind SCMI interface. See also: https://lore.kernel.org/all/be31801e-bb21-426b-f7aa-2b52727de646@quicinc.com/
2. Devicetree bindings for virtual systems and their devices.
3. Common board-id property for identifying DTS by bootloaders. See also: https://lore.kernel.org/all/20240521-board-ids-v3-0-e6c71d05f4d2@quicinc.com/
4. "Configuration" parameters for SoC components, like I2C timings or thermal characteristics, based on fused values. The board with given SoC comes with one DTS, but the SoCs have different packages and bins or the board have different characteristics like I2C bus speed. Depending on the board configuration or the fused SoC values, we might need to customize certain device properties (e.g. I2C timings or thermal values). See also: https://lore.kernel.org/linux-devicetree/20240701151231.29425-1-kyarlagadda@nvidia.com/
5. Versioning of same board DTS, e.g. when using in A/B testing for customers - DTS could have little differences like pin configuration.
6. Reference counting DT properties, aka fixing property memory leaks on device tree overlay removal. See also: https://lore.kernel.org/all/20240624232122.3cfe03f8@booty/
This is part for bigger topic - runtime hotplug on non-discoverable busses with device tree overlays, see other session where we might discuss it more: https://lpc.events/event/18/contributions/1696/
7. Pleasu..., ekhm, pain points when working with Devicetree schema (dtschema).
8. Linux kernel is the source of DTS, so it might get DTS purely for other projects (e.g. OpenBSD). Such DTS was never tested with Linux and might not work, but having it in the kernel creates impression that it is being supported.
9. Using Linux kernel DTS in U-Boot (aka OF_UPSTREAM)
As of today, the vast majority of accelerators for machine learning (NPUs, TPUs, DLAs, etc) lack a presence in the mainline kernel.
These accelerators can be used only with out-of-tree kernel drivers and binary-only userspace stacks, often forks of one or more open-source machine-learning frameworks. Companies are prey to vendor lock-in.
Companies selling accelerators are starting to react to the pressure from their customers and are exploring ways to mainline the drivers for their hardware.
Four drivers have been mainlined as of 6.10, but at least four other vendors have tried to mainline their drivers and seemingly abandoned the effort.
At this BoF we will discuss the challenges that existing drivers face, and how to make it easier for other vendors to mainline their drivers.
Agenda:
What is stopping vendors from mainlining their drivers and how could we make it easier for them?
Userspace API: how close are we from a common API that we can ask
userspace drivers to implement? What can be done to further this goal?
Automated testing: DRM CI can be used, but would be good to have a
common test suite to run there. This is probably dependent on a common
userspace API.
Other shared userspace infrastructure (compiler, execution,
synchronization, virtualization, ...)
Firmware-mediated IP: Can these drivers share a single codebase for their firmware?
Any standing issues in DRM infrastructure (GEM, gpu scheduler, DMABuf, etc)
that are hurting accel drivers?
GPU and accelerator interoperability: pipelines with graphics, compute and machine learning components, and also offloading portions of a model to a GPU and others to an accelerator.
The userspace which has a complex logic to manage the thermal envelope of the platform is often platform specific because custom kernels export clumsily interfaces to act on PM. Therefore, the userspace is often unusable when we want to support mainline kernels. That leads to more work as there are multiple userspace implementation to achieve the same goal. The objective of the discussion / proposal is to agree on interfaces we can use to have generic mechanism in userspace to act on performance, thermal and power without a knowledge of the hardware the logic is running on.
With the Linux Foundation becoming a CNA (https://docs.kernel.org/process/cve.html), the process around CVE assignment for kernel vulnerabilities has radically changed. Organizations maintaining downstream versions of the kernel have reacted differently, and those analyzing every CVE are struggling to keep up with the high volume of commits to process. This BoF session can be an opportunity to initiate a discussion on how to collaborate in this space, for those who can't keep their kernel upstream-aligned.
The Linux kernel has numerous tools to detect bugs, among them a family of dynamic program analysis called "sanitizers": Kernel Address Sanitizer (KASAN), Kernel Memory Sanitizer (KMSAN), Kernel Concurrency Sanitizer (KCSAN), and the Undefined Behaviour Sanitizer (UBSAN).
Knowing when to apply which sanitizer in the kernel development process may not always be obvious: each sanitizer is dedicated to finding a different class of bugs, and each introduces some amount of performance and/or memory overhead. Not only that, each sanitizer also provides a range of options to tweak their abilities.
This session is dedicated to briefly introducing each kernel sanitizer, the bug classes they help detect, and important gotchas when using them.
The rest of the session is dedicated to answering questions around each of the sanitizers, KASAN, KMSAN, KCSAN, and UBSAN. Feel free to also share success stories that may give other attendees only starting out with some of the sanitizers ideas how to best apply them.
Syzbot is a continuous kernel fuzzing system which automatically uncovers and reports hundreds of Linux kernel findings each quarter.
The session aims to foster open dialogue between the kernel engineers and those who operate syzbot. We'll discuss what's working well, where attention is needed, and how we can improve.
We plan to start by highlighting the key changes over the past year, known problems, and future syzbot/syzkaller development plans.
The majority of the session will be dedicated to discussing your experiences with Syzbot reports:
We had a very productive syzbot BoF discussion at LPC'23 and we're looking forward to seeing you again!
The KernelCI community is quite lively lately, so we want to take the opportunity to bring everyone interested in kernel testing together in the same room to discuss key priorities for the community. We invite kernel maintainers and developers, product developers, CI systems developers and different projects caring about testing, regression tracking and integration of the kernel.
How to facilitate the kernel community engagement with testing? How to get more benefits from the common database for test results with KCIDB? How to improve the quality of the tests? How to get to evergreen CI pipelines? So let’s discuss and figure out how each of us can help improve the Linux kernel integration across the ecosystem.
The Android MC Birds of a Feather allows space to further discuss important topics from the Android MC, and to also discuss some overflow topics that could not fit in the Android MC schedule.
This BoF will discuss topics such as:
* The state of fuse-over-io-uring and future plans
* Improving writeback performance
* famfs port into FUSE
* Extended write buffer sizes
The IMA namespace has been proposed a while ago but, despite many attempts at
addressing maintainers' concerns, it didn't get upstreamed yet. Our work tries
to determine if the IMA namespace fulfils the integrity requirements we
initially defined, and proposes a few suggestions on how to improve it.
Hello everyone,
We'll have a meeting today (20th of Sep) at 3pm in room 1.34.
You're welcome to join the discussion!
An open forum to discuss issues related to the Linux Security Module (LSM) framework and it's relation to the rest of the Linux kernel and low level userspace applications. Topics such as LSM stacking, LSM APIs (both kernel and userspace), and cross-subsystem issues are all welcome.
Integer overflows are a constant source of security problems. Someone needs to do something about it. We'll discuss new approaches using static analysis and runtime sanitizers. These approaches will require creating new rules for writing safe code. Most integer overflows are "harmless". For example, we used to have repeated security issues related to passing negative sizes to copy_from_user() but eventually Kees added a check for that so now passing a negative is "harmless". Under the new rules, many integer overflows which were "harmless" are now considered a bug. We want the new rules to be as effective as possible while balancing that against the burden of dealing with false positives.
We frequently are asked to triage and resolve "cgroup" bugs - from both
internal customers and Oracle Linux users. Cgroups are intertwined throughout
the entire kernel, and so users are often interacting with cgroups when they
encounter an issue. But rarely do the problems end up being a cgroup issue.
This has been a significant time sink for us.
To combat this, we've developed an automated test suite for cgroups, from
a kernel and userspace perspective as well as cgroup v1 and v2. We are
running the latest upstream kernels and the latest Oracle Linux kernels
against kernel self tests, LTP, and libcgroup's functional tests. After
that, we are running the kernel against various cgroup microbenchmarks.
The goals of this project:
* Find performance regressions - both upstream and in Oracle Linux
* Add test cases for legitimate bugs
* Generate known performance standards to compare against new releases
* Provide good cgroup usage examples to users
Areas of discussion:
* We will highlight our current setup and tests
* What setup (kernel config, hardware, etc.) would you like to see tested?
* What cgroup issues (real or noise) are others dealing with?
* What would others like to see tested?
* Are others interested in the results?
The RISC-V MC is limited to 1.5-3h, so we'll definitely spill over.
This BoF will discuss:
* maintainership
* testing/CI on QEMU
* testing/CI on HW
As server machines continue to get bigger, we face all types of kernel scalability issues. We'll discuss the implications of scalability, some recent patches in the area, and open areas of interest. In particular, we'll discuss the extent to which the kernel should proactively address these issues, when the solutions are far from free.
This is the traditional RCU Q&A session. If there are no questions, topics to be covered include explanation of the array of RCU flavors, recent changes in RCU, polling RCU APIs, expediting RCU callbacks, and possible improvements in the intersection between RCU and MM reclaim.
bpftrace is a hugely popular dynamic tracing technology for the Linux platform (https://github.com/bpftrace/bpftrace) leveraging eBPF. Its simple yet powerful scripting language, BpfScript, provides the ability to gain a new and fresh understanding of the entire software stack, from high level application APIs to the bowels of the kernel. Analyzing production performance problems and troubleshooting complex software stacks has never been easier.
Key contributors from the bpftrace engineering community will discuss the current and future direction of the technology. They will demonstrate how to use bpftrace to analyse different aspects of a system's behaviour. They also enjoy a challenge so bring your questions, issues, and ideas to see how bpftrace can be used to solve them!
Virtual Secure Mode (VSM) allows for the ability to run trusted software components within the guest. A paravisor is a trusted software component that runs inside the guest at a higher Virtual Trust Level (VTL), VTL2 that provides services for the guest running in lower VTLs. This can include providing enlightenments for unenlightened guests in a Confidential VM, or providing additional services to the guest in a normal VM, such as vTPM or device translation.
Here we introduce OpenHCL- a Linux based paravisor with a usermode virtualization stack written in Rust. OpenHCL is used in Azure today to provide device translation for legacy guests and vTPM for security. We'll also discuss some thoughts and learnings about writing a usermode VMM in Rust for a paravisor.
A demo will be shown with various different features of OpenHCL. The rest of the time will be dedicated to free form discussion or Q&A.
Confidential Computing microconferences in the past years brought together developers working secure execution features in hypervisors, firmware, Linux Kernel, over low-level user space up to container runtimes. A broad range of topics were discussed ranging from entablement for hardware features up to generic attestation workflows.
In the past year - guest memfd has been merged, TDX and SNP host support is getting closer to being merged. Next to go in will be support for ARM CCA and RISC V CoVE. In the meantime, there is progress being made on the Trusted I/O front.
But there is still some way to go and problems to be solved before a secure Confidential Computing stack with open source software and Linux as the hypervisor becomes a reality. The most pressing problems right now are:
Other potential problems to discuss are:
The Confidential Computing Microconference wants to bring developers working on confidential computing together again to discuss these and other open problems.
Key attendees:
The integration of Secure Virtual Machine Service Module (SVSM) with virtual Trusted Platform Modules (vTPMs) is a critical component in establishing trust and security for confidential virtual machines (CVMs). This session delves into the latest advancements in SVSM vTPM technology, covering a wide range of topics from boot attestation to persistent storage and future development directions.
We will explore how SVSM can be leveraged to perform early boot attestation within firmware, establishing a robust root-of-trust for CVMs. By unlocking persistent SVSM storage, we can provide a stateful vTPM and UEFI variable storage for Secure Boot, enhancing the overall security posture. Additionally, we will discuss extensions made to the keylime attestation framework to accommodate vTPMs and certify CVM attestation integrity through vTPM measurements at boot.
The session will also provide an update on the development status of the SVSM vTPM, highlighting key features and use cases. We will delve into the challenges and potential solutions for achieving persistent vTPM state in the context of confidential VMs, including discussions on guest identity provisioning, early boot attestation, early secret injection, and persistent storage.
Intel's Trust Domain Extensions (TDX) coupled with Coconut-SVSM is emerging as a powerful combination for secure and efficient virtualization. This talk delves into the intricacies of Intel TD Partitioning, its role in running an SVSM, and its integration with a virtual Trusted Platform Module (vTPM).
We will provide a comprehensive overview of TD Partitioning, explaining its architecture, functionality, and how it differentiates from traditional nested virtualization. The presentation will also cover the integration of TD Partitioning into the Coconut-SVSM stack, highlighting the challenges and solutions encountered during development.
A key focus of the talk will be on the vTPM solution built on top of Intel TD Partitioning and Coconut-SVSM. We will explore how this vTPM is implemented, including the generation of vTPM identity and the mechanism for user TD attestation. The potential benefits and use cases of this integrated solution will also be discussed.
A discussion of the requirements and trade-offs that led to the planes feature of the Arm Confidential Compute Architecture, as well as a description of the system as specified. This discussion will lead to the requirements for and a description of our proposed specification for inter-plane communication on Arm platforms.
Guest operating systems generally require modifications, referred to as enlightenments, to run under different Confidential computing architectures such as AMD SEV-SNP or Intel TDX. To support unenlightened guests, a software component called a paravisor is required. The paravisor runs at a higher privilege level within the guest to provide the appropriate abstractions and security guarantees that the unenlightened guest is unable to implement. The paravisor may additionally offer additional services such as emulated devices like a TPM or device translation between the host and the unenlightened guest.
Here we introduce OpenHCL - a Linux based paravisor with a usermode virtualization stack written in Rust for running unenlightened guests.
Transport Layer Security (TLS) is a widely used protocol for secure channel establishment. However, it lacks an inherent mechanism for validating the security state of the workload and its platform. To address this, remote attestation can be integrated in TLS, which is named attested TLS. In this talk, we present a survey of the three approaches for this integration, namely pre-handshake attestation, post-handshake attestation and intra-handshake attestation. We also present our ongoing research on Formal Verification of the three approaches using the state-of-the-art symbolic security analysis tool ProVerif to provide high confidence for use in security-critical applications.
Current project partners include TU Dresden, Arm, Bonn-Rhein-Sieg University of Applied Sciences, Barkhausen Institut, Linaro, Siemens, Huawei, and Intuit. By this talk, we hope to inspire more open-source contributors to this project.
The attendees will gain technical insights into attested TLS protocols for their use cases of attestation for confidential computing. We demonstrate to the attendees that the widely used Intel's RA-TLS protocol is vulnerable to replay attacks.
Benefits to the ecosystem
Our preliminary analysis shows that pre-handshake attestation is potentially vulnerable to replay and relay attacks. On the other hand, post-handshake attestation results in high latency. Intra-handshake attestation, potentially offering high security via formal verification and low latency by avoiding the additional roundtrip, may form a valuable contribution to the TEE attestation ecosystem.
In a nutshell, to provide more robust security guarantees, all applications can replace standard TLS with attested TLS.
As cloud technologies continue to advance at a rapid pace, there arises a critical need to assess the performance disparities among various virtualization stacks. This presentation aims to shed light on the comparative performance, scalability, and efficiency of two prominent hypervisor technologies—KVM/QEMU and Linux as Root Partition for Microsoft Hyper-V with Cloud-Hypervisor as VMM —within the realm of nested virtualization . Through a comprehensive evaluation, we will scrutinize diverse performance metrics encompassing CPU utilization, memory consumption, I/O throughput, and latency across varying workloads and configurations . Also, we try to examine the guest attestation process and the security aspects within these distinct hypervisor stacks. By delving into these key aspects, we seek to offer valuable insights into the operational characteristics and suitability of each hypervisor technology for nested confidential guest environments.
The secure and efficient transfer of data between confidential computing environments and the outside world is a critical challenge. This session brings together experts from different architectures to discuss the latest advancements in trusted I/O. We will explore the design principles, implementation details, and interoperability aspects of emerging standards such as RISC-V CoVE-IO, Arm CCA, AMD SEV-TIO and TDX Connect together with TDISP.
By understanding the commonalities and differences between these architectures, we aim to foster collaboration and identify opportunities for standardization and interoperability. The session will cover topics such as trusted device assignment, PCI pass-through, and the integration of trusted I/O into the Linux kernel.
The PCIe TEE Device Interface Security Protocol (TDISP, aka TEE-I/O) specifies requirements for a TEE Security Manager (TSM) on the host and a Device Security Manager (DSM) on a PCIe device, including an on-chip Root Complex-integrated Endpoint (RCiEP). TDISP also specifies protocols between TSM and DSM to establish trust between a confidential VM and a PCIe device or function, secure the connection between them, and attach and detach them in a trusted manner.
System-on-Chip (SoC) peripherals present unique opportunities and challenges when compared with PCIe peripherals – even compared with RCiEPs. On the one hand, being on-chip provides better architectural protection for the connection between confidential VM and peripheral. On the other hand, being on-chip and not bound to a standard interface specification enables low-level optimisations for power, performance and cost. These optimisations lead to a variety of options for secure management and peripheral partitioning as well as complex, cross-domain use cases.
As a result, there is a lack of common mechanisms to establish trust between a confidential VM and an SoC peripheral or to attach and detach them securely. PCIe TDISP and the corresponding Linux interfaces offer a promising starting point for a common abstraction between PCIe and SoC peripherals.
This presentation describes the opportunities and challenges with SoC peripherals and raises some directions for further exploration in adapting TDISP and its support in Linux.
This session will discuss the ongoing development of the RISC-V architecture for Confidential VM Extension (CoVE) and related CoVE-IO (for TEE-IO). The discussion will cover both the WIP ISA (CPU) and non-ISA (ABI, IOMMU and other platform aspects) extensions. The WIP ISA extensions will cover the proposed Smmtt (memory isolation) and related extensions for interrupts isolation, IO-MTT and external debug. The proposed CoVE ABI nears STABLE status and is entering the public review phase. The common aspects (that are cross-architectural) for Linux/KVM will be discussed to enable interoperability across different platforms for Confidential VMs. The discussion is to cover common flows that influence the public review of the specs by Q3'24.
Trustee, formerly referred to as KBS, is a set of attestation and key management services for confidential workloads. In the past year the project has grown considerably, now supporting attestation of 8 different confidential platforms. This talk will briefly introduce the project and these updates but the main focus is ongoing work.
The talk will touch on the community's plan to support device attestation and integrate the CoRIM and EAR standards. We will then dive more deeply into how Trustee can be used to provide secure networking services to confidential guests. We will discuss the limitations of existing networking solutions and the need for specialized approaches to address secure node discovery, attestation, and secret provisioning.
The Kernel Testing & Dependability Micro-Conference (a.k.a. Testing MC) focuses on advancing the current state of testing of the Linux Kernel and its related infrastructure.
Building upon the momentum from previous years, the Testing MC's main purpose is to promote collaboration between all communities and individuals involved with kernel testing and dependability. We aim to create connections between folks working on related projects in the wider ecosystem and foster their development. This should serve applications and products that require predictability and trust in the kernel.
We ask that all discussions focus on some identified issues, aiming at finding potential solutions or alternatives to resolving them. The Testing MC is open to all topics related to testing on Linux, not necessarily in the kernel space.
In particular, here are some popular topics from past editions:
Things accomplished from last year:
Benchmark test results are difficult to interpret in an automated fashion. They often require human interpretation to detect regressions because they depend on a number of variables, including configuration, cpu count, processor speed, storage speed, memory size, and other factors. Tim proposes a new system for managing benchmark data and interpretation in kselftest. It consist of 3 parts: 1) adding syntax to KTAP to support a consistent format for benchmark values in KTAP/kselftest test output, 2) the use of a set of criteria, external to the test itself, for interpreting benchmark result values, and 3) an automated tool to determine and set appropriate reference values to use in the test result criteria. A prototype system will be demonstrated, that supports converting benchmark values into KTAP "ok" and "not ok" results, consumable by humans and automated tools (such as CI systems). This system is intended to enable the detection of regressions in benchmark outputs, using appropriate threshold values that are customizable (in an automated fashion) by a tester for their own configuration and hardware.
There are several different testing frameworks for kernel and kernel-adjacent code, but KUnit is one of the most consistent and user-friendly. This means that KUnit is being used for things beyond its nominal scope of 'unit tests'. This includes stress tests, integration tests, and performance tests.
On the flipside, there are unit tests in the kernel tree for which KUnit's in-kernel nature is suboptimal. Some kernel code is self-contained enough that it can run (and be tested) without needing to boot an entire kernel (even a UML one). It's also convenient to be able to have smaller, faster tests to hand to other projects (e.g. compiler vendors). And some tools (e.g., perf) live in the kernel tree, but run in userspace, and so can't use KUnit directly.
These 'fully-userspace unit tests' currently use ad-hoc frameworks, which are often inspired by KUnit, but are not otherwise standardised. Can we improve this by:
- Developing a standard framework for 'fully-userspace tests'?
- Making this API as compatible with KUnit as possible (allowing, ideally, tests to be trivially ported back and forth, or run both in-kernel and in userspace)?
- Make it easier to use KUnit tools, features, and APIs outside a formal KUnit test?
Currently, kunit.py provides its own KTAP parser (in kunit_parser.py), specifically for KUnit use. While it can be used to parse KTAP from other sources, this is rarely done. This may be due to KUnit-specific features or difficulty accessing the parser. Unfortunately, this can lead to developers coding and maintaining other KTAP parsers that heavily overlap with this existing tooling.
We propose splitting kunit_parser.py into its own KTAP parsing and manipulation library and tool, independent of KUnit. This standalone interface can then be called by kunit.py and other testing frameworks to easily parse KTAP and produce "pretty-print" output. In the future, support for filtering, summarizing, combining/splitting KTAP, and converting to other formats can be added to this library, making it a "KTAP swiss-army-knife".
This new library would allow test frameworks to share resources, while also reinforcing the KTAP specification. Which frameworks would be interested in implementing this new library? What functions in addition to parsing should be offered? Are there changes to the KTAP specification that could improve the transition to using this general tooling?
We have been working on an LLVM-based toolchain for measuring test adequacy of existing kernel tests from test suites including KUnit [1], kselftest [2], LTP [3], test suites from RHEL [4] and more in KCIDB [5]. We measure different adequacy metrics including basic metrics statement coverage and branch coverage, and advanced metric Modified Condition/Decision Coverage (MC/DC) [6].
This talk is complementary to our proposed talk submitted to the Refereed Track. In this talk, we would like to present our results and share our analysis on the measured adequacy with different metrics, with a focus on the following aspects:
Reference
1. KUnit - Linux Kernel Unit Testing, https://docs.kernel.org/dev-tools/kunit/index.html
2. Linux Kernel Selftests, https://docs.kernel.org/dev-tools/kselftest.html
3. Linux Test Project, https://github.com/linux-test-project/ltp
4. Red Hat Kernel QE and CKI kernel tests repository, https://gitlab.com/redhat/centos-stream/tests/kernel/kernel-tests
5. Catalog of tests used by KCIDB, https://github.com/kernelci/kcidb/blob/main/tests.yaml
6. Making Linux Fly: Towards Certified Linux Kernel, https://elisa.tech/event/elisa-seminar-making-linux-fly-towards-certified-linux-kernel/
A large percentage of the functionality provided by the kernel to userspace
comes from the different devices in the system. For that reason, having a proper
common approach in mainline to test devices and detect regressions is of the
utmost importance for the kernel's reliability.
Devices are exposed through a diverse set of interfaces (uAPIs) and fully
testing them requires just as many, diverse, and complex testing frameworks.
Alternatively, by targeting the shared device framework, it becomes possible to
write generic tests that cover a lot of ground and require little maintenance.
One example is the device probe layer, which has been discussed during last
year's Plumbers [1] and has had a few tests merged [2] [3]. Another is the
device error logs, which are the universal mechanism for reporting errors in the
kernel, and for which a test is currently in review [4].
This session's goal is to provide a status update on the current generic device
tests, open the floor to gather feedback from the audience, and explore more
strategies to test device functionality at a generic level.
[1] https://lpc.events/event/17/contributions/1530/
[2] https://lore.kernel.org/all/20230828211424.2964562-1-nfraprado@collabora.com/
[3] https://lore.kernel.org/all/20240122-discoverable-devs-ksft-v4-0-d602e1df4aa2@collabora.com/
[4] https://lore.kernel.org/all/20240705-dev-err-log-selftest-v2-0-163b9cd7b3c1@collabora.com/
CI systems can generate a big amount of test results, so processing and interacting with that data in a timely, efficient manner is paramount. At KernelCI, we are investing a lot into improving the quality of the test results through automatic post-processing, grouping and filtering to find common patterns and surface the most important test failures to the kernel community.
In this session, we will quickly show some of the recent progress and open the mic for discussion and feedback. We are eager to learn about ways you want to interact with test results at KernelCI.
Among other things, we are progressing on a brand new web dashboard, automatically parsing logs and matching errors, automatically notifying of failures with string matching, identifying flakes, automatically grouping failures happening across different devices, trees, and configs, working with regzbot to facilitate tracking of relevant regressions, etc.
Introduce the librseq per-CPU user-space memory allocator. It implements concepts similar to the Linux kernel percpu allocator in userspace, and thus reduces waste of per-CPU data structures hot cache lines by eliminating padding usually required to eliminate false-sharing, and in addition tackles issues that arise from resident memory waste when restricting processes with scheduler affinity or cpusets.
It allows prototyping kernel algorithms within the safe limits of user-space.
Discuss open issues about interaction between use of shared and private file mappings within a process and the need to keep the shared mappings from being shared with children processes across fork.
A new mechanism, LUF(Lazy Unmap Flush), defers tlb flush until folios that have been unmapped and freed, eventually get allocated again. It's safe for folios that had been mapped read-only and were unmapped, as long as the contents of the folios don't change while staying in pcp or buddy so we can still read the data through the stale tlb entries.
tlb flush can be defered when folios get unmapped as long as it guarantees to perform tlb flush needed, before the folios actually become used, of course, only if all the corresponding ptes don't have write permission. Otherwise, the system will get messed up.
To achieve that, for the folios that map only to non-writable tlb entries, prevent tlb flush during unmapping but perform it just before the folios actually become used, out of buddy or pcp.
The result would depend on memory latency and how often reclaim runs, which implies tlb miss overhead and how many times unmapping happens. In my system, the result shows:
link: https://lore.kernel.org/lkml/20240531092001.30428-1-byungchul@sk.com/
While Car Audio is a commoditized technology, it’s still one of the sought after research area in automotive infotainment. The technology advancement in semiconductor technology has helped in integrating large IPs like DSPs, accelerators, analytics engines, etc into one single SOC, they have definitely resolved the requirement of low power, low cost, high performance requirements. But, the software integration possibilities have significantly out blown.
The RTOS, bare metal based software frameworks aren’t scalable to cater to range of devices in the audio segment on the other side the Zephyr or RT Linux doesn’t offer the platform required either. Moreover there are no open source frameworks or tools available which are proven and productized for automotive audio markets like auto amplifiers etc.
In this session we should be discussing the following :
- Software stack required to build few of the key audio centric solutions for automotive segments.
- Tools that are required to validate, standardize, configure and benchmark.
- What are latency requirements and other expectations – can RT Linux or Zephyr meet those.
- Can we build the required software stack on Zephyr or Linux.
- What are the safety constraints imposed for qualifying for the safety certifications (if any).
- Security, over the air upgrade, streaming media over the network – do they have to be proprietary ?.
Let’s leverage the opportunity to understand the domain requirements, available open source solutions, tools and standards that can help us in addressing the problems mentioned above, identify the gaps in Zephyr and RT Linux and prepare a community driven plan to address the same.
Fanotify is the filesystem notification framework in Linux. In recent years it has gained substantial amount of new features. In this talk we will survey developments in fanotify such as filesystem notification marks, reporting of directory events, support for unpriviledged users, marks that can be evicted in case of memory pressure, and others. In the end we will also outline features currently under development which will allow implementation of hierarchical storage management using fanotify.
Double scheduling is a concern with virtualization hosts where the host schedules vcpus without knowing whats run by the vcpu and guest schedules tasks without knowing where the vcpu is physically running. This causes issues related to latencies, power consumption, resource utilization
etc. An ideal solution would be to have a cooperative scheduling framework where the guest and host shares scheduling related information and makes an educated scheduling decision to optimally handle the workloads.
The initial approach was to have all the logic in KVM and this was discussed in LPC 2023 and upstream. KVM maintainers were not favourable with this idea as it puts a policies and decisions related to scheduling in KVM. And the resulting paravirt protocol is not generic. So the consensus is to have the policies and decisions as a separate entity which could be generic and implemented outside of kvm(A bpf program or kernel module).
We are working on the next revision where the guest and host implements the policies as a bpf program. Host exposes a virtual device through which initial handshake and negotiations happen and bpf program takes care of the guest/host communication, policies scheduling decision etc.
This talk is about our journey in designing a paravirt scheduling protocol, use of bpf while trying to maintain the generic nature of the protocol, advantages and challenges of bpf in this project etc. We would also be discussing the future of the project to include other use cases other than minimizing latencies..
The Linux kernel has supported multi-sized THP since v6.8 allowing the use of intermediate sized huge pages less than 2M. ARM64 supports contiguous PTEs where multiple PTE entries can be coalesced one TLB entry. This will increase the size of memory covered by the TLB entries and avoid page table walks to create TLB entries.
We ran a series of benchmarks on Ampere Altra using some popular workloads in cloud: In-memory databases, kernel compilation etc using different sized huge pages: 2M, 128K, 64K and others.
This presentation will also cover how multi-sized THP work and includes hardware details on the operation of contiguous PTE and variable page size on ARM64.
We conclude the multi-sized THP may not boost all kind of workloads. The overhead of page table walk is a significant contributing factor for some workloads. The reduced page faults help performance for some workloads. We would recommend the use of a kernel with 16K page size as an optimal solution that has most performance gains but does not significantly increase the memory footprint.
On almost all architectures, kdump has been the default or the only mechanism,
to capture vmcore - used for debugging kernel crashes, for close to couple of
decades. Fadump (Firmware-Assisted Dump [1], pronounced F-A-Dump) is being used
as the alternative dump capturing mechanism on ppc64, for over a decade.
This talk gives a brief introduction of kdump, why fadump was introduced and
how it is different from kdump, lists the advantages and pain points in both
kdump and fadump dump capturing mechanisms. Then briefly talks about what
pain points of fadump have been resolved in the past [and how]:
- relatively high memory reservation requirement for fadump [2]
- restrictions meant for kdump applied to fadump capture kernel, as it
also uses /proc/vmcore [3]
- same initrd used for booting production kernel and fadump capture
kernel [4]
Then gets into the crux of the talk by explaining:
How two major pain points for fadump have been resolved recently (v6.10)
1) Service downtime is needed to update resource information on CPU/Memory
hot add/remove operations. [5] ensures that this downtime is eliminated
completed by moving the resource information update to capture kernel.
2) Fadump doesn't support passing additional parameters to capture kernel.
Having that ability will help in disabling components that have high
memory footprint and/or complicate capture kernel boot process, but have
no real significance in capturing a vmcore. Memory preserving feature
of fadump is used to pass additional parameters to dump capture kernel [6].
The approach being considered to address the last major pain point for fadump -
coming up with the right reservation size for fadump capture kernel that works
for any system configuration. Explore if fixed reservation can be used for
fadump capture kernel irrespective of what the system configuration is, by
claiming additional memory required for capture kernel, if any, during capture
kernel boot itself.
Lastly, looks at how fadump fares against kdump and what is the architecture
support needed to enable/adapt fadump on other architectures.
[1] https://github.com/torvalds/linux/blob/master/Documentation/arch/powerpc/firmware-assisted-dump.rst
[2] https://lore.kernel.org/all/153475298147.22527.9680437074324546897.stgit@jupiter.in.ibm.com/
[3] https://lore.kernel.org/all/20230912082950.856977-1-hbathini@linux.ibm.com/
[4] https://lists.fedoraproject.org/archives/list/kexec@lists.fedoraproject.org/thread/RPPFTZJMA6HTG3LIBQC7UHX3O27IPO42/
[5] https://lore.kernel.org/all/20240422195932.1583833-1-sourabhjain@linux.ibm.com/
[6] https://lore.kernel.org/all/20240509115755.519982-1-hbathini@linux.ibm.com/
In the realm of operating systems, the heart of performance lies in the CPU scheduler: a critical component responsible for managing the execution of tasks on a system.
Traditionally, delving into CPU scheduling policies was largely confined to a small group of experienced kernel developers. Yet, there is an increasing aspiration to democratize this domain, facilitating experimentation and accessibility to a wider audience of researchers, developers, and learners.
scx_rustland is a fully functional Linux scheduler written in Rust, that runs entirely in user-space. It uses sched-ext and eBPF to channel scheduling events and communication between kernel and user-space.
One notable advantage of a user-space implementation is the availability of a large pool of debugging and profiling tools, libraries, and services. Moreover, with proper Rust's abstractions, developers can readily experiment with scheduling policies, without needing to navigate the complexities of deep kernel internals. This approach can help to lower the barrier of CPU scheduling experimentation and make this field more accessible to a wider audience of emerging kernel developers.
This scheduler is still in its proof of concept stage, however, with a well-defined API, it has the potential to evolve into an easily accessible user-space framework that allows to implement and test kernel scheduling policies.
This talk will cover the results obtained so far, highlighting the challenges faced, unsolved issues, and the trade-offs encountered along the way. The goal is to gather a feedback to pinpoint the necessary features and capabilities for defining the API for the generic scheduling subsystem.
The Linux kernel has grown in complexity over the years. Complete understanding of how it works via code inspection has become virtually impossible. Today, tracing is used to follow the kernel as it performs its complex tasks. Tracing is used today for much more than simply debugging. Its framework has become the way for other parts of the Linux kernel to enhance and even make possible new features. Live kernel patching is based on the infrastructure of function tracing, as well as BPF. It is now even possible to model the behavior and correctness of the system via runtime verification which attaches to trace points. There is still much more that is happening in this space, and this microconference will be the forum to explore current and new ideas.
This year, focus will also be on perf events:
Perf events are a mechanism for presenting performance counters and software events that occur running Linux to users. There are kernel and userland components to perf events, with the kernel presenting or extending APIs and the perf tool presenting this to users
15 years ago the perf events subsystem evolved from prior subsystems like OProfile, adding features like kernel profiling, tracing and system wide profiling. The subsystem continues to evolve, often driven by hardware, tracing and BPF developments. However, the purpose of this talk isn’t to look back at the perf event subsystem, the perf tool and ongoing improvements, it is to take advantage of a roomful of perf subsystem contributors and think about what is coming next and how to keep the subsystem fit for purpose.
Improving a subsystem would be beyond the time limit of any microconference talk. We aim to introduce broad topics, and have topics introduced to us, that can then serve as the basis for breakouts.
Areas for discussion include:
- Uncore events and sampling, modern and future topologies, the growth of accelerators.
- Context switch performance in the era of 100s of performance monitoring units.
- Scalability of perf events on heavily consolidated server platforms.
- BPF and perf event implementation convergence.
- The kernel PMU abstraction, challenges in its specification, use and implementation.
- Getting richer information at low cost, such as owner of locks during contention, extra details in stack traces.
- Overhauling points of pain, such as the mmap and lack of munmap, mremap events.
- PMU precise event abstractions on non-Intel and simplifying tool support.
- Kernel vs tool separation and licensing challenges.
- Perf tool evolution, performance, dependency and distribution challenges.
Recently perf tools added data type profiling which can find type information in the sample data using debug information (DWARF). It added the basic usage in the perf report and annotate with new sort keys. But it can be extended by more targeted commands like perf mem and perf c2c. We can discuss what it will be looked like and if there are other cases where the type info can be used.
Also using BTF instead of DWARF would be useful even if it has limited information. How to utilize the existing BTF or to extend it to be more useful would be a good discussion point as well.
Linux kernel supports many debugging feature. Tracing events by dynamic probes are one of them. This explains what kind of probes we already support and discuss what will be next. This will includes;
- Kprobes
- Fprobe/tprobe
- Eprobe
- Uprobe
- Perf probe and BTF
I developed kas-alias to address the issue of duplicate symbols in the kernel. This solution effectively handles duplicate symbols originating from the main kernel image binary and also provides a method for managing symbols in the modules.
However, the current implementation has a challenge that remains unresolved: it modifies an input file during the make process to insert aliases into the modules.
While this operation is minimally invasive, my goal is to integrate it into the make flow by altering the binary objects on the fly.
This approach aims to preserve the rest of the build logic specified in the kernel Makefile unchanged.
Unfortunately, the current modification violates a key principle of the make process, which is to avoid altering input files.
Implementing this intermediate file would require significant changes to the make structure, which I prefer to avoid.
In this miniconf presentation, I aim to discuss this issue and seek suggestions on alternative approaches to achieve the desired functionality without extensive modifications to the make system.
This talk is about a crazy idea that the Linux tracing ring buffers directly operate on your NIC tx/rx ring buffers. You may ask why? Doing that the whole Linux tracing subsystem gets Linux “networkified” as being part of the Linux networking ecosystem and you can do the same things like you do with all your other networking stuff. For example: classification, filtering, etc. Those operations can even be offloaded to your NIC hardware, sending your tracing data directly to a remote machine that analyzes it, accessing the data over a socket interface and many other things more. At the end you might need to explain to your IT why your “supposedly looking” unused networking card is still being used as a tracing offload engine.
I will explain the idea of how Linux tracing can be adapted into the Linux networking ecosystem and how already existing infrastructure in Linux networking can be used for Linux tracing data. That all makes Linux tracing hopefully faster and easier to use. This is just the beginning of implementing a whole new framework with the goal to handle distributed tracing with time synchronized tracing in Linux in a way that networking hackers like to use to debug their networks.
The goal of the SIDE specification is to enable instrumentation of various runtimes and languages. The libside library is a reference implementation of the SIDE specification for C/C++ user-space.
The SIDE specification covers:
It specifies how applications can be instrumented and how tracers can connect to that instrumentation.
The main discussion points proposed for this session are the integration of the SIDE specification with User Events and instrumentation of other runtimes.
There are scenarios where tracer inputs come from user-space and are not paged in. Tracepoints invoked at system call entry immediately after an exec(2) system call are very likely to require page faults to access arguments located in the ELF data section.
This issue is not limited to system call instrumentation, it also affects instrumentation ABIs such as User Events.
Discuss our "Faultable tracepoints" proposal [1], which lays the groundwork required to allow kernel tracers to handle page faults, and the approaches which can be taken by Ftrace, Perf, eBPF and LTTng to handle those faults.
[1] "Faultable tracepoints" https://lore.kernel.org/lkml/20240626185941.68420-1-mathieu.desnoyers@efficios.com/
The runtime verification utility has been in the kernel for a few years now. It is a way to actively verify that the system is acting as it expects to be by the use of creating a formal model, compiling it, and adding it to the kernel. Then it attaches to tracepoints and when one of those tracepoints is triggered, it moves the model state to the next node. If it tries to move to a state that is not allowed, it then will set off a trigger. A trigger could simply post a warning or it can panic the system. This is used by safety critical Linux. But there's more work to do on this. This discussion will be about how to take it further, as the main author is no longer with us.
The eBPF Track is going to bring together developers, maintainers, and other contributors from all around the globe to discuss improvements to the Linux kernel’s eBPF subsystem and its surrounding user space ecosystem such as libraries, loaders, compiler backends, related system tooling as well as eBPF use cases.
The gathering is designed to foster collaboration and face to face discussion of ongoing development topics as well as to encourage bringing new ideas into the development community for the advancement of the eBPF subsystem.
The track will be composed of talks, 30 minutes in length (including Q&A discussion).
eBPF Track's technical committee: Alexei Starovoitov, Daniel Borkmann, Andrii Nakryiko and Martin Lau.
While the BPF platform brings unique advantages not available elsewhere, it's rarely used in applications outside of the kernel. The natural explanation is to point out BPF's current limitations, and argue that it's only capable of supporting small, specialized programs.
To challenge these limitations, we venture into user-space with a suite of example projects, including a complete BPF port of Doom.
Built on top of νBPF (our home-grown BPF virtual machine), we push BPF to tackle use cases far outside of its usual comfort zone.
Using our experiences, we discuss the quality of life issues currently facing the ecosystem, both within the kernel and without. We address debugging and accessibility in particular, producing a prototype user-space debugger and a beginner-friendly Python interface.
The ability to safely extend OS kernel functionality is a longstanding goal in OS design, with the widespread use of the eBPF framework in Linux and Windows only underlining the benefits of such extensibility. However, existing approaches to kernel extensibility constrain users in the extent of functionality that can be offloaded to the kernel or the performance overheads incurred by their extensions.
We present KFlex: an approach that provides an improved tradeoff between the expressibility and performance of safe kernel extensions. KFlex separates the enforcement of kernel safety from the enforcement of extension correctness, and uses bespoke mechanisms for each to enable users to express diverse functionality in their extensions at low runtime overheads. We implement KFlex in the context of the Linux kernel, and our prototype is fully backward compatible with existing eBPF-based extensions, making it immediately useful to practitioners. Our evaluation demonstrates that KFlex enables offloading functionality that cannot be offloaded today, and in doing so, provides significant end-to-end performance benefits for latency-sensitive applications.
During our involvement in the development of Cloud Native networking for almost a decade, we learned the hard way that troubleshooting networking problems even in a small environment can turn into a nightmare. Many complexities stem from the Linux kernel itself - sending a packet involves dozens of kernel functions from different subsystems. Traditional tools such as tcpdump fall short, as they are often not fine-grained enough.
Our debugging frustration led to the creation of an eBPF-based networking debugging tool "pwru" ("packet, where are you?"). In the beginning, it only targeted the host networking stack. However, with the advent of eBPF-based networking more and more host networking functionality has been moved to BPF programs. Therefore, we started to extend the tool to support BPF program tracing.
First, in this talk, we will present the debugger's implementation. Next, we will talk about some limitations of the BPF subsystems we had to work around when extending the debugger. Finally, we will present a few interesting networking problems debugged with the tool.
This presentation will focus on the tooling for the BPF instruction-level memory model, an early prototype of which was demonstrated at LSF/MM/BPF. New features include control dependencies based on conditional branches along with additional atomic operations. This demo will include instruction on how to build the tooling and how to run it, along with some examples.
Attendees will be able to build the tool and run their own litmus tests, and inspect the wealth of litmus tests that have already been created.
To mitigate the Spectre-PHT (v1) vulnerability, mitigations which reject potentially-dangerous unprivileged eBPF programs have been merged into the kernel [1]. To assess their potential real-world impact, we analyze 364 object files from open source projects (Linux Samples and Selftests, BCC, Loxilb, Cilium, libbpf Examples, Parca, and Prevail) and find that this affects 31% to 54% of programs.
Motivated by this, we explore the possibility of mitigating Spectre-PHT using speculation barriers in eBPF. For this, we prototype the VeriFence [2] kernel patch set, which optimistically attempts to verify all speculative paths but falls back to speculation barriers when unsafe behavior is detected. As expected, this allows all real-world application programs in our dataset to be successfully loaded into the kernel with all mitigations enabled. We measure the overhead of VeriFence for event tracing and stack-sampling profilers, and find that it increases eBPF program execution time by 0% to 62%. Further, for the Loxilb network load balancer, we measure a 14% slowdown in SCTP performance but no significant slowdown for TCP. Besides discussing the feasibility of unprivileged eBPF as whole and whether mitigations should be enabled for privileged eBPF, we present the lessons learned and potential for optimizing the VeriFence prototype further.
The increase in memory capacity in datacenters, coupled with the proliferation of memory-intensive applications, has made memory management a significant performance bottleneck. This issue is poised to worsen due to several factors, such as the inherent hardware limits of TLB scaling and the advent of terabyte-scale memory capacity through technologies like CXL.
In this talk, I will present our vision of a programmable memory management interface with eBPF that can provide a pliable solution. Specifically, the discussion will cover our ongoing work on (a) ensuring contiguity for larger translations, such as huge pages, and (b) introducing learned virtual memory management, a novel solution based on lightweight machine learning, that can effectively address the bottleneck of address translation.
Previous work on implementing the Static Keys for BPF [1], [2] led to the introduction of an "instruction set" map. This map contains pointers to xlated BPF instructions and is relocated accordingly during load and verification.
The instructions set map can be further used to verify indirect jump instructions in BPF, which wasn't approachable before. Namely, a goto Rx instruction can be linked to such a map, which lets the verifier check every possible branch taken.
The goal of this talk is to discuss the design and implementation of the BPF indirect jumps API and to list existing problems and restrictions of its usage.
[1] https://lpc.events/event/17/contributions/1608/
[2] http://vger.kernel.org/bpfconf2024_material/bpf_static_keys.pdf
Currently, the only way to attach a piece of information to an sk_buff that will travel with it through the network stack is the mark field.
Once set, the mark can be read in firewall rules, used to drive routing, and accessed by BPF programs, among other uses. This versatility leads to fierce competition over the mark’s bits. Being just 32 bits wide, it often ends up limiting its practical applications.
Interestingly, there is already support for attaching more than just four bytes of metadata to a packet from the XDP context. In this presentation, we want to discuss how to extend this concept so that packet metadata can be accessed by other BPF programs which run later in the stack on the RX path, such as sk_lookup, reuseport, and socket filter.
Furthermore, we want to examine how packet metadata could be consumed by user-space programs using well-known patterns from the socket API, such as socket options and ancillary messages (cmsg).
During the talk, we would also like to highlight how attaching rich metadata to packets enables new and exciting applications such as:
* Tracing packets through layers of the network stack, even when crossing the kernel-user space barrier.
* Metadata-based packet redirection, routing, and socket steering with early packet classification in XDP.
* Extraction of information from encapsulation headers and passing it to user space, or vice versa.
We also want to explore how metadata could be structured to allow different users to share it without interference by leveraging the power of BTF based on prior work in that field.
Datacenter workloads have demanding performance requirements, including the need for high throughput and low tail latency while maintaining high server utilization. While modern hardware is compatible with these goals, overheads and inefficiencies in today's operating systems remain a critical bottleneck. Several research proposals aim to address this problem by designing dataplane OSes with specialized I/O stacks and scheduling algorithms. However, these proposals have poor backwards compatibility, and lack broader hardware support. There also exist proposals which use eBPF to offload application logic into the kernel, and bypass the OS layers to provide better performance. However, these lose multi-tenancy and isolation between competing workloads, and require rewriting applications.
In this talk, we will discuss an approach that provides similar performance, isolation, and multiplexing benefits as existing proposals while retaining the backwards compatibility and reliability of the Linux I/O stack. Our approach is based on the observation that the bottlenecks in the Linux I/O stack are due to how execution resources are allocated to each stage of I/O processing, and not due to inefficiencies in individual I/O stack components. So, we believe eBPF-driven extensibility can address this by allowing workload-specific specialization of the I/O data path, balancing the functional and performance requirements datacenter workloads. Finally, eBPF programs can provide the necessary abstractions to stitch together request processing logic of applications across user and kernel mode, providing an end-to-end solution.
Currently CRIU mainly relies on procfs and extended system calls for dumping/restoring process information, but this has some performance and extensibility problems. In this talk, we want to discuss CRIB (Checkpoint/Restore In eBPF), an innovative checkpoint/restore method to dump/restore process information in the kernel via eBPF. CRIB can achieve better performance, more flexibility, more extensibility (easier to support dumping/restoring more information), and more elegant implementation. CRIB consists of three parts, CRIB userspace program, CRIB ebpf programs, and CRIB kfuncs. With this design we can still keep most of the complexity outside the kernel. CRIB could provide a new and better engine for CRIU. Complete descriptions of CRIB can be found in the patch series 1 2.
HID-BPF was announced at Plumbers 2022 in Dublin. Since then, it has been merged in the kernel v6.3 and started to see its first users. The promises were big, and I can now safely say that they actually delivered.
In this talk we will first give an overview of what has been done in these 2 years. We already have a few success stories to share. But this was just the beginning. And now that the first steps have been taken, it is time to enhance HID-BPF. Which is why we will then focus on the new developments for HID-BPF and what has been done in BPF core to support even more use cases. Lastly we will reflect on our future objectives but also the drawbacks that we saw and can expect to see with such a technology.
While there are eBPF libraries for languages like Rust and Go, there are none for Java, one of the most popular programming languages. We developed the hello-ebpf Java library to change this. Its aim is to integrate eBPF programs seamlessly into Java applications, making it possible to write the eBPF programs themselves directly in Java.
In this talk, we show the technology behind the library, its use, and how to use it to easily implement a basic packet filter and a simple Linux scheduler without writing a single line of C code.
The IoT and Embedded Micro-conference is a forum for developers to discuss all things IoT and Embedded. Topics include tools, telemetry, device drivers, protocols and standards in not only the Linux kernel but also Real-Time Operating Systems such as Zephyr.
Current Problems that require attention (stakeholders):
Since last year, there has been a number of significant updates on the topics discussed at IoT MC:
One topic we'd like to cover in detail is technology or standards to help improve boot time. If there is work in this area, on Linux or Zephyr, we'd like to hear about it. Examples of boot time reduction, or of fast un-hibernate from low-power state would be welcome. Also, we're interested in discussing ideas for standards for passing pre-initialized hardware to Linux at kernel boot time.
We hope you will join us either in-person or remote for what is shaping up to be another great event full of collaboration, discussion, and interesting perspectives.
Boot time plays an important role in defining the user experience of a product, the more time it takes in getting the device into action the quicker it is pulled out of the stands.
Linux & it’s stacks can be tweaked to boot as quickly as possible but the challenge is beyond just optimizing the flow – it gets into defining the use cases to go after – to – productizing these features and deploying in test farms and delivering to customers.
In this session I would like to share with you the challenges of optimizing boot time and productizing these optimizations.
Problem 1 : Identifying those minimum & complicated Fixed Functions : (should be optimized by default)
Examples:
- Authentication : Best possible authentication of Image.
- Boot media : OSPI NAND / NOR fetch, eMMC reads, etc.
- Power : Resume latency, suspend latency.
Problem 2: Tweaking the flow for individual Use cases (individual) :
Examples:
- Early Audio
- Early Display with Graphics.
- Early Ethernet, CAN
Problem 3: Dealing with Combined Use cases (combo) :
Examples:
- Networking + Display
- Networking + Camera + decode / encode
- Audio + Display
Problem 4 : Accelerated with MCU cores and Linux late attach (Late attach) :
Examples:
- Early display and taken over by A core after boot
- Early audio from boot loader and control taken over by Linux post boot.
Problem 5: Packaging & Delivery of optimizations
Examples :
- Document with build and reproducible steps ? where to host such documentation ?
- wic image on yocto ? with bbappend patches ?
Problem 6: Maintenance & long term support
- Moving along with kernel versions and file system revisions.
- Test automation possibilities ( how to ensure tweaks can be deployed in farm)
The Linux kernel currently lacks common upstream terminology for measuring
boot time. Although tools like ftrace are available to trace boot-time
events, there is no standardized approach (and upstream kselftest!) to
measure and identify slowdowns during different stages of the boot process.
In this session, we will explore how to leverage existing tracing tools to
monitor key events in the boot sequence and propose building a kselftest to
automate this process. Building an in-tree test eliminates external
dependencies and standardizes usage across different users and CI systems.
The discussion will cover identifying critical functions to trace,
configuring ftrace (e.g. through bootconfig), parsing trace data, and
comparing it to user-provided reference values to detect significant boot
time regressions.
In this session, we will propose an approach for building such test and
invite community feedback and discussion.
This session is intended to present and discuss 3 different technology areas surrounding boot-time reduction for Linux systems: 1) boot time markers, 2) boot phases, and 3) profile-guided boot-time optimizations. Boot-time markers is a proposed set of well-define measurement points in the Linux boot process, used for testing improvements and regressions in boot time. "Boot phases" refers to dividing the kernel boot process into two distinct phases: a time-critical phase and non-time-critical phase, and investigating how to initialize time-critical drivers and features, while still supporting full operation of a system in the long term. Finally, profile-guided boot-time optimizations refers to utilizing run-time data from one instantiation of the kernel, to drive the optimization of subsequent instantiations, through things like an init data cache, that holds probed values, that can be incorporated into re-compilations of the kernel source to shorten boot times on dedicated or specialized hardware. Finally, I would like to discuss how to instantiate a working group of developers in the area of boot time reduction, when there is no centralized maintainer for this "feature" of the kernel.
This session will discuss the current problems faced for the linux-wpan/ieee802154 subsystem. We will have small problem statements before discussion on ongoing work and clarification of requirements:
Marc (Linux kernel CAN subsystem maintainer) and Oleksij (Linux kernel J1939 maintainer) will give an overview of current best practices for the Linux CAN subsystem and J1939 stack.
They will address high latencies in the RX path, presenting a two-step approach to avoid buffer overflows and out-of-order reception using the RX-Offload helper.
Modern CAN controllers provide RX and TX-complete time stamps. In order to use them in user space, they need to be converted from the CAN controller's internal clock to the kernel representation in nanoseconds. Marc and Oleksij will give a short introduction to the cyclecounter/timecounter helpers that should be used by new drivers.
They will also discuss future goals like configurable CAN frame queuing (FIFO vs. priority) and using ethtool for CAN HW filter configuration.
Updates on the J1939 stack adoption, validation efforts, and user space ecosystem enhancements will also be covered.
New embedded products are being developed by the industry having add-on boards that can be hot-plugged to the main board to extend features, and do so using busses not natively hot-pluggable and discoverable such as USB or PCI. Instead they use busses that are traditionally not removable such as I²C, SPI, and even more complex ones such as MIPI DSI.
Currently Linux is unable to handle such situations. This session aims at discussing how to solve the main blocker issues.
What needs to be supported for such products is add-ons that:
The most suitable tool to handle this use case appears to be device tree overlays, which already provide most of the required functionality. However using overlays exposes a number of problems.
This topic has been discussed informally during an unconference session at ELC 2024 and a series with a proposed implementation [Ceresoli 2024 v4].
Other related but different use cases include:
Topics to discuss:
Other topics that might be discussed:
In Linux based IOT embedded applications there has always been this ongoing desire to attach MCUs (Micro-Controller Unit) to MPUs (Micro-Processor Unit) running Linux. The usual reason is that the MCU is able to handle low latency data processing more efficiently then the higher-level functioning MPU. The MCU might also add a missing peripheral on the MPU that is more system cost efficient. The data passed between the two processors can be as simple as a couple of register values to something more complex such as streaming low-level protocol traffic. Typically, a specific driver for a specific MCU has to be developed and up streamed before a connection can be made. This can restrict choices for a project that can impact overall development time. This presentation is about proposing a generic device driver to be up streamed for connecting MCUs from an application perspective to an MPU that would allow the Linux side to provide a common framework for connecting MCUs. The MCU side would have a framework to develop code to pass data with.
As part of the presentation an example application will be discussed that shows connecting an MCU collecting data that is then passed to a Linux application. As part of the discussion the complexity of the data being passed will be considered and whether the data type and amount is not suitable for a generic approach. The overall goal would be to have a generic kernel driver that would attach over a peripheral interface such as SPI and be able to communicate with the MCU without having a dedicated driver.
A key capability of this driver would enable application developers to start their project without having to wait for a specific up streamed kernel driver.
Memory management has become exciting again. Some controversial subjects which might merit discussion:
Memory allocation profiling infrastructure provides a low-overhead mechanism to make all kernel allocations in the system visible. This allows for monitoring memory usage, tracking hotspots, detecting leaks, and identifying regressions.
Unlike previous discussions on the design of this technique, we will now focus on the changes since it was incorporated into the upstream kernel, planned future improvements, and initial discoveries within the Google fleet using Memory Allocation Profiling.
The discussion will cover ongoing improvements to reduce the overhead of this feature (minimizing metadata), enhance support for modules (decrease overhead when allocations persist at unload), improve observability (provide access to certain GFP flags data), adding context capture for select allocations and covering more allocators.
Initial discoveries will be based on our experiences deploying memory allocation profiling on a portion of the Google fleet. We will provide an analysis of the collected data, focusing on reducing kernel memory overheads.
The desired outcome of this discussion is to identify a reduction plan for the top allocation call sites and determine which other call sites to investigate next.
For decades, Linux memory management has been mostly focused on the needs of
user space and generic kernel-space users (memory control groups, transparent
huge pages, compression). Other big changes are good for maintenance and/or
debugging (removal of DISCONTIGMEM, compaction, kmemleak, folios, removal of
redundant slab-style allocators and many other). Little has been done for device
drivers (only CMA comes to mind).
It appears that Linux memory management does not match the needs of device
drivers very well. At some point, the ugly, quirky and subtly or grossly
broken hardware kicks in and spoils the party. It's usually the job of device
drivers to bridge the gap. They often have to care about the placement of
memory buffers in physical address space. Surprisingly or not, these
constraints rarely match the constraints of DMA and DMA32 zones (if they even
exist). As a result, these zones add complexity to the buddy allocator but
they do not bring much benefit. CMA may help sometimes but not always.
I would like to discuss the alternatives and possible ways to remove DMA and
DMA32 from the kernel.
There are two hopes for Linux kernel. Some people hope the kernel to just works without users' intervention. Meanwhile, some people hope the kernel be extensible so that the users can flexibly control the kernel with their proprietary information.
DAMON is designed and planned to convince the two parties. Also, because DAMON is a part of memory management subsystem, it should also convince other memory management subsystem developers.
This session will share and discuss the long term plan for the goal with other memory management subsystem developers. Especially, I hope to get concerns and possible solutions about the plan in terms of the stability and maintenance burden of the entire memory management subsystem.
vma guards are inserted at the start and/or end of vmas to detect out-of-bound reads or writes. Currently these guards are represented by an allocated vma even though almost all the information in the vma is not used. Sometimes these guards are so numerous that they represent close to half of the vmas used in a system. Such a large number of underutilized objects represents a potential for significant space savings. I would like to discuss a more efficient way to implement the same functionality using "poison" and "remedy", which will jilt the vma guards from the next generation of allocators.
Conventional wisdom has held that madvise overhead has been mostly the syscall overhead. However, profiling shows this not to be the case.
Even on a medium sized 1 socket system, about half the CPU time spent in MADV_DONTNEED is spent flushing the TLB, and that is just in the calling CPU. Add in handling of the TLB flush IPIs on the other CPUs, and 90-95% of the MADV_DONTNEED overhead is TLB flushes.
I would like to propose MADV_LAZY_FREE, which can avoid most of the TLB flush overhead through collaborative behavior with the malloc library, and some inspiration from RCU.
Direct and passthrough IO involves mapping user space memory into the kernel. At present, this memory is mapped as an array of pages. Using 4K pages for mapping results in additional overhead due to per-page memory pinning, unpinning, and calculations. Switching to a large folio-based mapping will reduce this overhead.
As part of this proposal, the current GUP implementation needs to be updated to use folios. This change must address the following aspects:
During the transition to a 16kb page size system, numerous instances were found where the kernel or userspace relied on the assumption of PAGE_SIZE == 4096. While many functional issues have been resolved, some inherent challenges persist, along with opportunities for optimization in systems with larger page sizes.
This work investigates the following key challenges and potential areas of optimizations:
The swap system original only need to handle 4K and THP size swap. When mTHP introduce more size option for swap, it also bring new challenge of the swap fragmentation. The swap sub system will need some change for the new allocation requirement.
The presentation will propose some swap allocator approaches to address the mthp swap fragmentation. Some of the patch series already send to the mail list.
In addition to the work by Chris Li and Ryan Roberts on optimizing mTHP swap-out slot allocation [1][2], we at OPPO have several patchsets focused on mTHP swap-in [3][4] and enhancing zsmalloc/zRAM [5] to save and restore compressed mTHP.
Without mTHP swap-in, mTHP is a one-way ticket: once swapped out, they cannot revert to mTHP. With mTHP swap-in, we make mTHP bidirectional and gain the ability to compress and decompress large folios, significantly improving compression ratios and reducing CPU usage.
This topic will cover the current progress on mTHP swap-in and mTHP compression/decompression in zsmalloc/zRAM. It will also initiate a discussion on the appropriate policies for determining the optimal mTHP swap-in size for various swap files, such as zRAM and SSD, with a particular focus on zRAM in our current work.
[1] https://lore.kernel.org/linux-mm/20240618232648.4090299-1-ryan.roberts@arm.com/
[2] https://lore.kernel.org/linux-mm/20240614-swap-allocator-v2-0-2a513b4a7f2f@kernel.org/
[3] https://lore.kernel.org/linux-mm/20240529082824.150954-1-21cnbao@gmail.com/
[4] https://lore.kernel.org/linux-mm/20240629111010.230484-1-21cnbao@gmail.com/
[5] https://lore.kernel.org/linux-mm/20240327214816.31191-1-21cnbao@gmail.com/
TAO is an umbrella project aiming at a better economy of physical contiguity viewed as a valuable resource. A few examples are:
1. A multi-tenant system can have guaranteed THP coverage while hosting abusers/misusers of the resource.
2. Abusers/misusers, e.g., workloads excessively requesting and then splitting THPs, should be punished if necessary.
3. Good citizens should be awarded with, e.g., lower allocation latency and less cost of metadata (struct page).
4. Better interoperability with userspace memory allocators when transacting the resource.
The cornerstone of TAO is an abstraction called policy zones, and that new abstraction has its own proposal: https://lpc.events/event/18/abstracts/1981/
There are three types of zones:
1. The first four zones partition the physical address space of CPU memory.
2. The device zone provides interoperability between CPU and device memory.
3. The movable zone commonly represents a memory allocation policy.
Though originally designed for memory hot removal, the movable zone is instead widely used for other purposes, e.g., CMA and kdump kernel, on platforms that do not support hot removal. Nowadays, it is legitimately a zone independent of any physical characteristics. In spite of being somewhat regarded as a hack, largely due to the lack of a generic design concept for its true major use cases, the movable zone naturally resembles a policy (virtual) zone overlayed on the first four (physical) zones.
This proposal formally generalizes this concept as policy zones so that additional policies can be implemented and enforced, to for example optimize page allocations based on properties known at allocation time, or even runtime. Those properties include memory object size and mobility, or hotness and lifetime, respectively.
Jon at LWN kindly wrote a nice article on this topic: https://lwn.net/Articles/964239/
As Linux is increasingly deployed in systems with varying criticality constraints, distro providers are being expected to ensure that security fixes in their offerings do not introduce regressions for customer products that have safety considerations. The key question arises: How can they establish consistent linkage between code, tests, and the requirements that the code satisfies?
This MC addresses critical challenges in requirements tracking, documentation, testing, and artifact sharing within the Linux kernel ecosystem. Functionality has historically been added to the kernel with requirements explained in the email justifications for adding, but not formalized as “requirements” in the kernel documentation. While tests are contributed for the code, the underlying requirement that the tests satisfies is likewise not documented in a consistent manner.
Potential topics to be discussed:
Last year, we had several talks on the need for safe systems [3][4] in various domains with Linux as a component (with varying safety criticality levels). This miniconference is targetted at getting those interested together, and working up a framework for collecting relevant evidence and sharing it.
MC Leads:
Kate Stewart, Philipp Ahmann
Potential Participants:
Syed Mohammed Khasim
Jonathan Corbet
Shuah Khan
Greg Kroah-Hartman
Chuck Wolber
Nicole Pappler
Thomas Gleixner
Gabrielle Paoloni
Olivier Charrier
Jiri Kosina
Joachim Werner
Paul Albertela
Bertrand Boisseau
[1] https://docs.kernel.org/admin-guide/workload-tracing.html
[2] https://digital-strategy.ec.europa.eu/en/policies/cyber-resilience-act
[3] https://lpc.events/event/17/contributions/1499/
[4] https://lpc.events/event/17/contributions/1518/
In regulated industries, Linux is widely used due to its strong software capabilities in areas such as dependability, reliability, and robustness. These industries follow best practices in terms of processes for requirements, design, verification, and change management. These processes are defined in standards that are typically not accessible to the open source kernel community.
However, since these standards represent best practices, they can be incorporated into structured development environments like the Linux kernel even without the knowledge of such standards. The kernel development process is trusted in critical infrastructure systems as it already covers many process elements directly or indirectly.
The purpose of this session is to initiate a discussion on what is currently available and what may be missing in order to enhance the dependability and robustness of Linux kernel-based systems. How can the artifacts be connected? Where are the appropriate places to maintain them? And who is the best responsible for each element of the development lifecycle?
VirtIO is a specification for virtual devices that describes how devices and drivers are defined and how they interact. For example, the specification defines the steps that a driver has to follow to initialize a virtio-device. The specification defines what is expected from a driver when communicating with a virtio-device. This specification has been used to develop virtio-drivers and virtio-devices in different languages and technologies. For example, QEMU implements virtio-devices in C. Rust-vmm implements virtio-devices in Rust. Recently, the specification has been used to build virtio-devices in hardware. Also, there are different implementations of the drivers depending on the operating system, e.g, Linux, Windows or baremetal. To ensure compatibility between different implementations, developers must ensure that the implementation conforms to the VirtIO specification. This is a manual task that relies on testing the implementation during different use cases. In this talk, we present a proof-of-concept solution that aims to systematically verify that a virtio-driver conforms to the VirtIO specification. During this exploratory work, we focus on a small section of the specification, which is the device lifecycle VIRTIO_CONFIG_S_* status register state machine. This section specifies the steps that a virtio-driver has to follow to initialize a virtio-device. We propose to encode these steps by using the Clock Constraint Specification Language (CCSL). This is a formal language that allows expressing the specification in terms of events and timing relationships between these events, e.g, causality. Then, we use this specification to check whether a virtio-driver follows the VirtIO specification. To do this, we use the ftrace interface to observe the execution of the virtio-driver. We apply our approach the traditional virtio memory balloon device to manage guest memory. During the initialization of the driver, violations to the specification are immediately informed to the user on the dmesg console. The aim of this talk is to present the approach and to have face-to-face discussions and debate about the benefits, drawbacks and trade-offs. We report take away lessons and present the tools to get the community familiar with the workflow.
The Linux Kernel does not come with comprehensive and complete architectural design documentation and yet such information is needed to support technical analyses in critical industries (e.g. functional safety) and can be useful for both maintainers and developers along the standard Linux Kernel development.
The Kernel is partitioned in drivers and subsystems, with associated maintainers controlling the respective code contributions.
How can we visualize dependencies between different subsystems? How to visualize the SW resources handled by each subsystem or shared between different subsystems?
ks-nav is a working in progress tool, in the miniconf I want to discuss and seek advice for a couple of features I want to add to ks-nav:
We have been working on measuring Linux kernel's source-based code coverage using LLVM toolchain. Prior coverage testing tools like gcov instrument the target kernel at the IR level and do not have a precise mapping back to the source code. If compiler optimizations are enabled (which is the default for building Linux kernel), coverage will not map well to the source code, and the reports are oftentimes confusing. To solve this problem, source-based code coverage [1] does instrumentation at the compiler frontend and maintains accurate mapping from coverage measure to source code locations. Source-based results can reflect exactly how the code is written and can present advanced metrics like branch coverage and Modified Condition/Decision Coverage (MC/DC) [2] in a human friendly way. Comparison of these two tools using real kernel code examples can be found in [3].
This talk is complementary to our proposed talk submitted to the Refereed Track. This talk is a deeper dive of our work on supporting advanced testing towards certifying Linux.
Reference
We will discuss how to let the BASIL project grow in terms of users and developers with focus on possible future applications and on the roadmap of new features development.
The increasing demand to create, maintain and exchange information at least about the hight level requirements as well as the applied software engineering methods does not stop for open source projects.
In the open source ecosystem we have a fantastic advantage - we can both exchange the relevant data freely and we are free from legacy lock in usage of ancient lifecycle and requirements management tooling. These tools, in combination with the fear to expose too much IP, lead to useless efforts - we are talking manual copy/pastes of thousands of requirements! Plus Excel lists to track these efforts.
There are now several fantastic solutions out there to use open source tools for lifecycle management, from git based systems to fully open source requirements management solutions.
Yes, this growing zoo of tools can lead us to the same issues that these commercial dinosaurs are facing.
This talk will leverage how using the SPDX Safety Profile as an open and standard exchange format is avoiding all this pain and pitfalls that we have seen for commercial product development.
If a bug is a violation of expectations, a safety bug is a violation of expectations that places the user at an elevated risk of injury. From this perspective there is little distinction between Safety Engineering and Security Engineering; a safety bug can arise from a failure to perform, regardless of engineering discipline. Yet, the practice of each discipline is driven by opposing philosophical viewpoints. Where Safety Engineering seeks to develop deterministic behavior under specified conditions, Security Engineering is tasked with defending against generally unspecified conditions.
In this talk, Chuck will review the Cinder Block Problem and explore the philosophical underpinnings of Safety and Security Engineering. He will use the distinction between safety hazard and security threat to establish positive ("shall") and negative ("shall not") views of engineered systems. Chuck will use these views to show that safe systems are not necessarily secure and secure systems are not necessarily safe. Striking a feasible balance requires an understanding of each view and the independent application of these philosophically opposed engineering disciplines.
This session is meant to:
There are a variety of artifacts and processes that are helpful in performing analysis of the Linux kernel. Discussing where the artifacts should be stored, and the processes around building trust on these crowd sourced artifacts, is needed to build up some agreement with kernel community.
X86-focused material has historically been spread out at Plumbers. This will be an x86-focused microconference. Broadly speaking, anything that might affect arch/x86 is on topic, except where there may be a more focused discussion occurring, like around Confidential Computing or KVM.
This microconference would look at how to address new x86 processor features and also look back at how older issues might be made less painful. For new processor features like APX, what is coming? Are the vendors coordinating and are they compatible? For older issues like hardware security vulnerabilities, is the current approach working? If not, how should they be dealt with differently? Can new hardware features or vendor policies help?
As always, the microconference will be a great place for coordination among distributions, toolchains and users up and down the software stack. All the way from guest userspace to VMMs.
Potential Problem Areas to Address:
This presentation will describe the growing complexity of mitigations for CPU side-channel vulnerabilities, the challenges they pose to the Linux kernel and what we can do to minimize the performance impact. It will also present the difficulty of maintaining various mitigation options, and the intrusive nature of mitigations that affect the core areas like context switch and kernel entry/exit points. To give an idea on this growing complexity, since 2018 nearly 20 new X86_BUG_* have been added. During the same period x86 bugs.c alone grew from 62 to ~3000 LOC. The presentation will finally explore the challenges of ensuring comprehensive protection while minimizing impact on system performance. Probing the possibility of new modes and trust model that aims to spare the hammer on trusted applications.
There are currently more than a dozen command line options related to x86 CPU speculation bugs, and it takes a security expert to understand them all and when they can be safely disabled. This talk will discuss a recent RFC that proposes simpler “attack vector” based controls which would allow admins to select a set of mitigation options based on how the system is being used. For instance, if the system only runs trusted VMs, then guest-to-host mitigations should be disabled. The goal is to make it easier to select appropriate and consistent mitigation options, and potentially recover lost performance.
The x86_64 exception handling relies on complex indirect system structures such as the IDT and TSS. This process can sometimes involve complicated stack switching, which further complicates the situation when it comes to ring changes, syscall gaps, unblockable reentrant IST exceptions, the increasing number of Coco-introduced IST exception types, the nesting of the IST exceptions, and so forth, along with the necessity for accurate switching of GSBASE, CR3 or other bits related to mitigations.
The dancing of the IST stacks represents a major challenge; the NMI stack-switching had led to CVEs and the current more cumbersome and burdensome #VC stack-dancing adds more strain. The varied approaches used by different exceptions exacerbate the issues, making them more entrenched.
In this session, we introduce a new Integral Atomic Stack Switching mechanism. This mechanism aims to consolidate the diverse segregated stack-switching processes and handle all the essential event-handling states in a unified, atomic manner. We will explore the current problems, outline the design of the mechanism, examine how it addresses the issues, and discuss other potential derived benefits, such as enabling shadow stacks in the kernel.
Address Space Isolation (ASI) is a technique to mitigate broad classes of CPU vulnerabilities.
ASI logically separates memory into “sensitive” and “nonsensitive”, the former is memory that may contain secrets and the latter is memory that, though it might be owned by a privileged component, we don’t actually care about leaking. The core aim is to execute comprehensive mitigations for protecting sensitive memory, while avoiding the cost of protected nonsensitive memory. This is implemented by creating another “restricted” address space for the kernel, in which sensitive data is not mapped.
At LSF/MM/BPF this year I presented a conceptual overview and discussed strategy and some implementation details of interest to the mm community. [LWN]
I'm now in the process of preparing an updated RFC, the code is available and I plan to post it on LKML in the coming days. I'd like to spend this MC slot discussing feedback and questions that I expect the RFC to provoke. Some examples include:
Discussion with the mm community didn't produce any strong objections either way. I'm currently hoping to start with a denylist, on the basis of "launch and iterate". Do x86 folks support this strategy?
Configuration of existing mitigations is organised on a per-vulnerability basis. ASI does not target any specific vulnerability. It also presents a new type of "policy" question to kernel users since it is not strictly equivalent to any other set of mitigations, as it works by deliberately dropping protection for certain data. How should ASI be enabled and how should this interact with existing defaults?
How should ASI interact with KPTI? I think it's always going to be a defensible security posture to enable ASI and KPTI at the same time (although I don't imagine Google will ever do this). But do we want to support this complexity? Should ASI eventually replace KPTI? Assuming the answer is no, how entangled should the implementations be for these two features?
Opinions of the new "critical section" concept that ASI introduces in order to deal with interrupts occuring in the guest/userspace return path.
Discussion of the fact that ASI can make CR3 unstable even when preemption is disabled.
Other interesting topics that are less specifically x86-relevant include:
First a quick update on what is done for FRED in Linux upstream, and then some improvements/fixes/refactors that we are doing or going to do. Lastly and most importantly an overview of future FRED features will be presented.
At last year's Refereed Track, we introduced the "x86-cpuid-db" project and discussed its rationale for the Linux Kernel, the Xen hypervisor, and other plumbing layer open-source projects.
This year, the author will present a demo and initiate a discussion on the refactorings of the Linux Kernel's x86 subsystem and a new X86_FEATURE flags' dependency data model that are to be submitted mainline—all leveraging the x86-cpuid-db project's auto-generated files.
Prior to the XSAVE introduction, managing the processor's context state
was handled on a per-feature basis. XSAVE normalized this by making state
management independent of the CPU feature set. The XSAVE architecture has
since evolved with optimizations, such as compacting the state format and
tweaks for efficient reloads, resulting in a few XSAVE variants.
This monolithic approach to state management has accommodated the
addition of around 10 features, expanding the overall state size to more
than 10KB from the initial 1KB at the time of XSAVE's introduction about
20 years ago. Despite this growth, the unified approach has effectively
prevented fragmentation and reduced the complexity that would arise from
managing feature-specific state additions.
During the initial consideration of XSAVE, extensive discussions focused
on the context format in the signal stack. It was emphasized that the new
XSAVE format should be backward-compatible, and self-describing. Then,
the XSAVE uncompacted format was adopted as part of user ABI, considering
CPUID to universally provide the size and fixed offsets while trusting
its proper extensions.
As the XSAVE architecture continued to embrace more feature states, some
of these features were excluded in other CPU implementations. This
uncovered a limitation in the uncompacted format, which proved inflexible
in adapting to these dynamic changes. Unfortunately, the new compacted
format cannot serve as a drop-in replacement for the user ABI, as it is
incompatible with the uncompacted format.
This inflexibility has recently posed challenges in managing large states
like AMX. Given this context, it is worthwhile to revisit the XSAVE story
as a case study from both architectural and kernel perspectives. In the
long run, it may be beneficial to discuss an alternative to the hardware
format. Additionally, considering architectural mitigation could address
the current limitations of the monolithic approach.
Memory Protection Keys (pkeys) was originally an Intel-only CPU feature to protect userspace memory. Since its introduction, support has materialized for powerpc, AMD and ARM, and Intel has expanded the original implementation to cover kernel memory.
There have been a number of attempts to expand the original implementation.
Let's take stock of where the original implementation stands and consider if protection keys use should be expanded to cover kernel memory or if the userspace ABI should be enhanced to cover more use cases.
Details will be listed on the back of you badge.